So we have a cube with N columns, trying to simulate one with n columns. For N=4, we use grouping G={2,2} to simulate n=2, and G={1,2,1} to simulate n=3, with obviously G={1,1,1,1} being the default N=n=4; Where |G|=n. Clearly this is just ways to split up our integer N into different sized sets, subject to certain conditions we hope to derive along the way.
For example, we cannot use 4={1,1,2} as an emulator for n=3, because on the left side we have a face by itself, but we on the right we have the face paired off with an edge section. This means that when solving it, it'll eventually be split up. EG the two (Face, Direction) rotations: (Bottom, Left), (Left Up) would separate part of the 2x2 simulated cube initially in the bottom right corner. This is because of the lack of symmetry in the {1,1,2} expression. IE if we have tiles 'a' and 'b' in the 3rd emulated set (--,--,ab), after a rotation we have (a,b,--), which will then be separated upon moving either column. So we need each tile to be paired with just as many pieces on one side as the other, thus our given emulator distribution MUST be symmetrical.
For all N>3, we we have N={1,(n-2),1}, which is of course symmetrical and has magnitude 3, thus an n=3 cube can always be emulated for any N. For N=5, we also have G={1,3,1}={2,1,2} for n=3 emulation. We cannot have n=2, because we have 5 columns to pair off to our 2 emulated sides. Since we cannot split this evenly, it is not possible. Now in terms of symmetry, it depends on if we have an odd or even number of columns, thus if we have a central column or not.
IE for n odd, we need its central column to be emulated, done differently depending on if N is odd or even. If N is even, we can do this by having equal amounts of columns adjacent to the central divide as being treated as a single block. EG {1,2,1} gives us an emulated central column, so n=3 can be done inside N=4. Note here that the size of that central column (2) is even, but if we have N odd, then the central column in N does not get split up, but instead needs to be bunched with equal amounts of columns on both sides, thus we would have the size of the middle string being odd. EG for n=3 inside N=5, gives G={1,3,1}={2,1,2}, where both middle columns have odd numbers. Hence we have a solution for N odd. Either way, n odd can be emulated in both N even and N odd.
But for n even, we need to split the columns of N into an even amount, one which is clearly impossible if N is odd, thus N also needs to be even. Thus N odd can emulate only n odd, N even can emulate n both odd or even. This is true for All N>n, for example:
N=4. {1,1,1,1}, {1,2,1}, {2,2}.
N=5. {1,1,1,1,1}, {1,3,1}={2,1,2}.
N=6. {1,1,1,1,1,1}, {1,1,2,1,1}, {1,2,2,1}={2,1,1,2}, {1,4,1}={2,2,2}. {3,3}.
N=7. {1,1,1,1,1,1,1}, {1,1,3,1,1}, {1,5,1}={2,3,2}={3,1,3}.
N=8. {1,1,1,1,1,1,1,1}, {1,1,1,2,1,1,1}, {1,1,2,2,1,1}={1,2,1,1,2,1}={2,1,1,1,1,2}, {1,1,4,1,1}={1,2,2,2,1}={2,1,2,1,2}, {1,3,3,1}={3,1,1,3}={2,2,2,2}, {1,6,1}={2,4,2}={3,2,3}, {4,4}.
So Odd cubes can only emulate smaller odd cubes. Even cubes can emulate all smaller cubes. Basically because the emulation will take the symmetric form of either G={---k---,---k'---} or G={--k--,m,--k'--}; thus giving total group size=emulator size of the form a+a=2a=even, or a+b+a=2a+b which can be made even or odd.














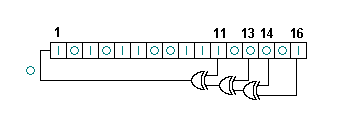
 - The internal state of the Galois LFSR above (lower image) can be represented by the polynomial given by sum(ith bit is 1) xi, where the leftmost bit is bit 0 and bit position counts left to right. Example above: 1+x2+x4+x5+x8+x9+x10+x15.
- Cycling the Galois LFSR is as simple as multiplying the polynomial internal state by x and taking the remainder upon division by the reverse of the LFSR's polynomial 1+x2+x3+x5+x16.
- Let f(x) be the reverse of the LFSR's polynomial and p(x) be the initial Galois LFSR state. Then the question is: what is the smallest positive n such that f(x) divides p(x)(xn-1)?
- Factor f(x) into irreducible factors f1(x)f2(x)...fk(x). Then for each irreducible factor that does not divide p(x), the question is: what is the smallest positive ni such that fi(x) divides xni-1?. If f(x) itself is irreducible, then it cannot divide p(x) (since deg f > deg p) unless p(x) is the zero polynomial.
- Even if f(x) is irreducible, that doesn't necessarily mean that the LFSR has period 2deg f-1 (the maximum) for nonzero initial values. In order for that to happen, the smallest positive n for which f(x) divides xn-1 must be 2deg f-1. In this case, f(x) is a primitive polynomial (field theory definition of primitive, not gcd definition).
- Note that every polynomial with nonzero constant term is a divisor of xn-1 for some n. In particular, an irreducible polynomial g(x), other than x, is a divisor of x^(2deg g-1)-1. This follows from field theory but I won't go into it here.
At this point, it is easier just to do small examples. The polynomials of interest are the reversals of xn+xn-1+1, that is, xn+x+1.
n=5:
x5+x+1=(x2+x+1)(x3+x2+1).
Note that both x2+x+1 and x3+x2+1 are primitive polynomials.
Let p(x) be the polynomial for the initial Galois LFSR state. Let g(p(x))=(u(x),v(x)) where u(x) is remainder of p(x) divided by x2+x+1 and v(x) is remainder of p(x) divided by x3+x2+1 (this is unique by the Chinese Remainder Theorem).
If g(p(x))=(0,0) (p(x) is the zero polynomial), then the cycle has length 1.
If g(p(x))=(u(x),0) for nonzero u(x), then the cycle has length 22-1=3 (since x3+x2+1 divides p(x), its only contribution is from x2+x+1)
If g(p(x))=(0,v(x)) for nonzero v(x), then the cycle has length 23-1=7.
If g(p(x))=(u(x),v(x)) for nonzero u(x) and v(x), then the cycle has length gcd(3,7)=21; this covers all possible values as well.
n=8:
x8+x+1=(x2+x+1)(x6+x5+x3+x2+1).
Note that both x2+x+1 and x6+x5+x3+x2+1 are primitive polynomials.
Let p(x) be the polynomial for the initial Galois LFSR state. Let g(p(x))=(u(x),v(x)) where u(x) is remainder of p(x) divided by x2+x+1 and v(x) is remainder of p(x) divided by x6+x5+x3+x2+1.
If g(p(x))=(0,0) (p(x) is the zero polynomial), then the cycle has length 1.
If g(p(x))=(u(x),0) for nonzero u(x), then the cycle has length 22-1=3.
If g(p(x))=(0,v(x)) for nonzero v(x), then the cycle has length 26-1=63.
If g(p(x))=(u(x),v(x)) for nonzero u(x) and v(x), then the cycle has length gcd(3,63)=63. For a given v(x), there are 3 possible values for u(x) in order to cover all possible values; thus, this gives 3 classes of length 63, for a total of 4.
n=9:
x9+x+1 is irreducible.
Now since the smallest positive n such that x9+x+1 divides xn-1 is n=73 (instead of n=29-1=511), x9+x+1 is not primitive. In fact, if p(x) is the initial Galois LFSR state, and p(x) is not the zero polynomial, then the cycle has length 73. There are 7 such cycles. Of course, if p(x)=0, then the cycle has length 1.
Now, it's pretty hard to characterize the factorizations of xn+x+1, even if polynomial factorization can be done quickly (faster than integer factorization for sure). The only other thing I can say is that x2+x+1 is always a divisor of xn+x+1 when n=2 (mod 3), and xn+x+1 is always square-free, since the gcd of xn+x+1 and its derivative is always 1. That's about it.
Here are full factorizations of xn+x+1 (mod 2) from n=2 to 20. The symbol * after a factor means that it is not a primitive polynomial; in this case the smallest m for which it divides xm-1 is given.
x2+x+1
x3+x+1
x4+x+1
x5+x+1=(x2+x+1)(x3+x2+1)
x6+x+1
x7+x+1
x8+x+1=(x2+x+1)(x6+x5+x3+x2+1)
x9+x+1*
x10+x+1=(x3+x+1)(x7+x5+x4+x3+1)
x11+x+1=(x2+x+1)(x9+x8+x6+x5+x3+x2+1)
x12+x+1=(x3+x2+1)(x4+x3+1)(x5+x3+x2+x+1)
x13+x+1=(x5+x4+x3+x+1)(x8+x7+x5+x3+1)
x14+x+1=(x2+x+1)(x5+x3+1)(x7+x6+x5+x2+1)
x15+x+1
x16+x+1=(x8+x6+x5+x3+1)(x8+x6+x5+x4+x3+x+1)*
x17+x+1=(x2+x+1)(x3+x+1)(x12+x11+x10+x9+x8+x6+x4+x+1)*
x18+x+1=(x5+x2+1)(x13+x10+x8+x7+x4+x3+x2+x+1)
x19+x+1=(x3+x2+1)(x4+x+1)(x5+x4+x2+x+1)(x7+x5+x4+x3+x2+x+1)
x20+x+1=(x2+x+1)(x5+x4+x3+x2+1)(x13+x11+x10+x9+x7+x4+1)
x9+x+1: 73
x8+x6+x5+x4+x3+x+1: 85
x12+x11+x10+x9+x8+x6+x4+x+1: 273
- The internal state of the Galois LFSR above (lower image) can be represented by the polynomial given by sum(ith bit is 1) xi, where the leftmost bit is bit 0 and bit position counts left to right. Example above: 1+x2+x4+x5+x8+x9+x10+x15.
- Cycling the Galois LFSR is as simple as multiplying the polynomial internal state by x and taking the remainder upon division by the reverse of the LFSR's polynomial 1+x2+x3+x5+x16.
- Let f(x) be the reverse of the LFSR's polynomial and p(x) be the initial Galois LFSR state. Then the question is: what is the smallest positive n such that f(x) divides p(x)(xn-1)?
- Factor f(x) into irreducible factors f1(x)f2(x)...fk(x). Then for each irreducible factor that does not divide p(x), the question is: what is the smallest positive ni such that fi(x) divides xni-1?. If f(x) itself is irreducible, then it cannot divide p(x) (since deg f > deg p) unless p(x) is the zero polynomial.
- Even if f(x) is irreducible, that doesn't necessarily mean that the LFSR has period 2deg f-1 (the maximum) for nonzero initial values. In order for that to happen, the smallest positive n for which f(x) divides xn-1 must be 2deg f-1. In this case, f(x) is a primitive polynomial (field theory definition of primitive, not gcd definition).
- Note that every polynomial with nonzero constant term is a divisor of xn-1 for some n. In particular, an irreducible polynomial g(x), other than x, is a divisor of x^(2deg g-1)-1. This follows from field theory but I won't go into it here.
At this point, it is easier just to do small examples. The polynomials of interest are the reversals of xn+xn-1+1, that is, xn+x+1.
n=5:
x5+x+1=(x2+x+1)(x3+x2+1).
Note that both x2+x+1 and x3+x2+1 are primitive polynomials.
Let p(x) be the polynomial for the initial Galois LFSR state. Let g(p(x))=(u(x),v(x)) where u(x) is remainder of p(x) divided by x2+x+1 and v(x) is remainder of p(x) divided by x3+x2+1 (this is unique by the Chinese Remainder Theorem).
If g(p(x))=(0,0) (p(x) is the zero polynomial), then the cycle has length 1.
If g(p(x))=(u(x),0) for nonzero u(x), then the cycle has length 22-1=3 (since x3+x2+1 divides p(x), its only contribution is from x2+x+1)
If g(p(x))=(0,v(x)) for nonzero v(x), then the cycle has length 23-1=7.
If g(p(x))=(u(x),v(x)) for nonzero u(x) and v(x), then the cycle has length gcd(3,7)=21; this covers all possible values as well.
n=8:
x8+x+1=(x2+x+1)(x6+x5+x3+x2+1).
Note that both x2+x+1 and x6+x5+x3+x2+1 are primitive polynomials.
Let p(x) be the polynomial for the initial Galois LFSR state. Let g(p(x))=(u(x),v(x)) where u(x) is remainder of p(x) divided by x2+x+1 and v(x) is remainder of p(x) divided by x6+x5+x3+x2+1.
If g(p(x))=(0,0) (p(x) is the zero polynomial), then the cycle has length 1.
If g(p(x))=(u(x),0) for nonzero u(x), then the cycle has length 22-1=3.
If g(p(x))=(0,v(x)) for nonzero v(x), then the cycle has length 26-1=63.
If g(p(x))=(u(x),v(x)) for nonzero u(x) and v(x), then the cycle has length gcd(3,63)=63. For a given v(x), there are 3 possible values for u(x) in order to cover all possible values; thus, this gives 3 classes of length 63, for a total of 4.
n=9:
x9+x+1 is irreducible.
Now since the smallest positive n such that x9+x+1 divides xn-1 is n=73 (instead of n=29-1=511), x9+x+1 is not primitive. In fact, if p(x) is the initial Galois LFSR state, and p(x) is not the zero polynomial, then the cycle has length 73. There are 7 such cycles. Of course, if p(x)=0, then the cycle has length 1.
Now, it's pretty hard to characterize the factorizations of xn+x+1, even if polynomial factorization can be done quickly (faster than integer factorization for sure). The only other thing I can say is that x2+x+1 is always a divisor of xn+x+1 when n=2 (mod 3), and xn+x+1 is always square-free, since the gcd of xn+x+1 and its derivative is always 1. That's about it.
Here are full factorizations of xn+x+1 (mod 2) from n=2 to 20. The symbol * after a factor means that it is not a primitive polynomial; in this case the smallest m for which it divides xm-1 is given.
x2+x+1
x3+x+1
x4+x+1
x5+x+1=(x2+x+1)(x3+x2+1)
x6+x+1
x7+x+1
x8+x+1=(x2+x+1)(x6+x5+x3+x2+1)
x9+x+1*
x10+x+1=(x3+x+1)(x7+x5+x4+x3+1)
x11+x+1=(x2+x+1)(x9+x8+x6+x5+x3+x2+1)
x12+x+1=(x3+x2+1)(x4+x3+1)(x5+x3+x2+x+1)
x13+x+1=(x5+x4+x3+x+1)(x8+x7+x5+x3+1)
x14+x+1=(x2+x+1)(x5+x3+1)(x7+x6+x5+x2+1)
x15+x+1
x16+x+1=(x8+x6+x5+x3+1)(x8+x6+x5+x4+x3+x+1)*
x17+x+1=(x2+x+1)(x3+x+1)(x12+x11+x10+x9+x8+x6+x4+x+1)*
x18+x+1=(x5+x2+1)(x13+x10+x8+x7+x4+x3+x2+x+1)
x19+x+1=(x3+x2+1)(x4+x+1)(x5+x4+x2+x+1)(x7+x5+x4+x3+x2+x+1)
x20+x+1=(x2+x+1)(x5+x4+x3+x2+1)(x13+x11+x10+x9+x7+x4+1)
x9+x+1: 73
x8+x6+x5+x4+x3+x+1: 85
x12+x11+x10+x9+x8+x6+x4+x+1: 273



