Joined: 3/25/2006
Posts: 850
Location: stuck in Pandora's box HELLPP!!!
Warp wrote:
Which, in conjunction to the previous postulate, means that logx(2) is never rational for rational values of x?
Not quite.
logx(2) is rational iff log2(x) is rational (for x != 1).
log2(x) = a/b iff x = 2a/b, and we note that b must be one, so x must be a power of two (including negative powers).
In particular, log1/2(2) = 1 / log2(1/2) = -1
Now I'm a bit confused. Let's recap:
Premise: 21/n is irrational for any rational value of n > 1.
This means that for 21/n to be rational, n must be irrational.
We can even give a formula for what n must be. In other words, if we have:
21/n = r
where r is rational, then
n = log(2)/log(r), ie. n = logr(2).
From this, in conjunction with the premise, it follows that n cannot be rational. (Any rational value of n would give an irrational result, which r is not, as we established r to be rational.)
Thus it follows that if logr(2) is larger than 1, it must be irrational for any rational value of r.
Is there a flaw in this deduction?
Joined: 3/25/2006
Posts: 850
Location: stuck in Pandora's box HELLPP!!!
No flaw, but do note that the case for n = logr(2) for r = 1/2 gives n = -1 which does not satisfy n > 1 which is a condition for the premise.
What we find is that n = logx(2) for co-rational (x,n) is satisfied by x = 2k for any integer k != 0:
log2k(2) = 1 / log2(2k) = 1 / (k log2(2)) = 1/k
We also note that -1 <= 1/k <= 1 for integer k.
Joined: 12/28/2013
Posts: 396
Location: Rio de Janeiro, Brasil
EDIT: There are some things wrong in what I said here, I'm trying to fix them.
The chance of getting no number in the right spot is [(n-1)/n]^n
The change of getting exactly one number, however, is (1/n)*n*[(n-1)/n]^(n-1), so, [(n-1)/n]^(n-1), which is a higher chance.
Getting 2 numbers would be (n*(n-1)/2n²)*[(n-1)/n]^(n-2)
So, lets divide these last 2 possibilities:
{(n*(n-1)/2n²)*[(n-1)/n]^(n-2)}/{[(n-1)/n]^(n-1)} = [(n*(n-1)/2n²)]/[(n-1)/n] = n²*(n-1)/[(2n²)*(n-1) = 1/2.
So, getting one number is 2 times more likely than getting 2, and also more likely than getting 0. So, it should be the most likely amount of numbers to get.
If I have the first n natural numbers arranged in a random order, how many would you expect to be in their correct locations?
The expected value of the number of numbers is their correct locations (1 in 1st, 2 in 2nd, etc.) is the sum of the expected values of the functions "1 if number i is in correct location, 0 otherwise" over all i from 1 to n. Since (n-1)! of the n possible orders have number i in the correct location, the expected value is n*(n-1)!/n! = n*(1/n) = 1.
The orders are commonly known as "permutations" and a number in its correct location is known as a "fixed point". As an aside, note that the number of permutations with exactly k fixed points is C(n,k) dn-k, where di is the ith derangement number. So the expected value is Sum{0≤k≤n} (k C(n,k) dn-k / n!). This gives an identity:
Sum{0≤k≤n} (k C(n,k) dn-k / n!) = 1.
thanks, FractalFusion. I was going a much more laborious route and had computed an expected value of 1 for n up to 4 but was getting bogged down. Your method is much more elegant.
Okay, but what is the chance of getting exactly one number wrong?
I am still the wizard that did it.
"On my business card, I am a corporate president. In my mind, I am a game developer. But in my heart, I am a gamer." -- Satoru Iwata
<scrimpy> at least I now know where every map, energy and save room in this game is
I am still the wizard that did it.
"On my business card, I am a corporate president. In my mind, I am a game developer. But in my heart, I am a gamer." -- Satoru Iwata
<scrimpy> at least I now know where every map, energy and save room in this game is
I've been thinking about a simplified problem involving farming:
Imagine that you're growing a crop on an infinite amount of farmland, starting with a certain number of seeds A (natural number), with average yield per seed y>1 (that is, if you plant A seeds, you'll most likely get yA seeds for the next harvest). Each season, you save a certain portion of seeds r (0<r<1) for the next season and eat the rest. Somehow, the yield per seed does not change as a result of practices like overusing the same plot of soil or tilling the rest of the plant back in (because only the seeds have value), and the present value of the seeds depreciates by a factor of k (0<k<1) per season, so the average present value of a seed's yield is v=ky.
If N is the number of seeds available per harvest, and t is the number of seasons since the beginning (whole number), then N=A*(yr)^t, so to keep this enterprise going, r>=1/y.
If H is the total number of seeds harvested after T seasons (whole number), then
H=sum(A*(1-r)(yr)^t,t,0,T)=A*(1-r)(1-(yr)^(1+T))/(1-yr)
If r>=1/y then H grows without bound as T->infinity, otherwise H->(1-r)A/(1-yr).
For this case, dH/dr=(y-1)A/(1-yr)^2, which is positive because y>1, so the total harvest grows without bound as r->1/y.
Now, let V be the net present value of the harvests, then
V=sum(A*(1-r)(vr)^t,t,0,T)=A*(1-r)(1-(vr)^(1+T))/(1-vr).
What is important to note here is that although it is possible for v>=1, this is not guaranteed, but what is guaranteed is that 1/y<1/v; if v<1, then r<1<1/v, so V=(1-r)A/(1-vr). Then dV/dr=(v-1)A/(1-vr)^2<0, so the ideal strategy to maximize net present value is to save no seed (r=0) and consume it all without planting.
If v>=1 then it is possible for r=1/v, and then V=(1+T)(1-1/v)A, which grows without bound as T->infinity.
The curious thing happened when I tried to maximize the net present value over limited timescales; in this case,
dV/dr=(v*(1-r)(vr-1)(T+1)(vr)^T-(1-v)(1-(vr)^(1+T)))/(1-vr)^2
so dV/dr=0 when
v*(1-r)(vr-1)(T+1)(vr)^T=(1-v)(1-(vr)^(1+T))
and although I was able to see that this means r=1/v for the cases T=0, T=1, T=2, T=3, and T=4, (after eliminating the extraneous roots), and that r=1/v is a root in the general case, it's curious that WolframAlpha wasn't able to solve this equation for r or at least figure out that r=1/v is always a root, not even with the sophisticated non-elementary functions that it knows about.
Joined: 4/20/2005
Posts: 2161
Location: Norrköping, Sweden
I have another math problem that I encountered in a project at work. I haven't been able to solve it in an elegant way (I've made a pretty ugly pragmatic solution, see below), but I would like to present the problem to you in the hopes that you may have an elegant and clever way to solve it
So the situation is that I have a set of point x1, x2, ..., xn and y1, y2, ..., yn. I want to fit a polynomial of degree n to these points (n is usually in the range 2-5, but it can vary, so don't necessarily limit yourself to these values). The "normal" way to solve this would of course be to just make a least squares fit and get a polynomial y=p(x). However, I have certain requirements of the polynomial p(x) I require it to be non-decreasing between values x_lower and x_upper (formally p'(x)>=0 for x_lower <= x <= x_upper).
One valid subset that would work is when all the coefficients are >0, but this would be too limiting. My own solution to this was to a apply a general optimization method and simply punish the fit measure if the polynomal was decreasing in this interval, making it want to avoid any such polynomal. But I'm sure there is a better way to approach this. And thoughts on this?
If H is the total number of seeds harvested after T seasons (whole number), then
H=sum(A*(1-r)(yr)^t,t,0,T)=A*(1-r)(1-(yr)^(1+T))/(1-yr)
I think I disagree with your formula for harvested seeds. If we have seeds xi, of which we keep ki and eat/harvest hi, we have:
x0=A
x1=yx0=yA, k1=rx1=ryA, h1=(1-r)x1=(1-r)yA
x2=yk1=ry2A, k2=rx2=r2y2A, h2=(1-r)x2=(1-r)ry2A
x3=yk2=r2y3A, k3=rx3=r3y3A, h3=(1-r)x3=(1-r)r2y3A
...
xt=ykt-1=rt-1ytA, kt=rxt=rtytA, ht=(1-r)xt=(1-r)rt-1ytA
Thus we have
H=Sum{hi, i=0, t} = Sum{(1-r)ri-1yiA, i=0, t} = (1-r)A Sum{ri-1yi, i=0, t}
=(1-r)A (y+ry2+r2y3+...+rt-1yt)
=(1-r)A ( y(1-(ry)t+1)/(1-ry) )
At some point I realized that the Cantor's diagonal argument technically speaking is a demonstration that the set of all possible infinite strings of digits is uncountable. (If we assumed that we can enumerate all possible infinite strings of digits, the argument shows that the assumption leads to a contradiction.)
Technically speaking that in itself doesn't yet prove that the set of reals is uncountable. We would still need to prove that the set of reals has the same size as the set of all possible infinite strings of digits.
I'm not completely sure that's trivial, given that some different strings of digits represent the same real number.
^I believe that is covered in typical classes on real analysis and follows from the fact that all pairs of infinite digit strings representing the same number represent rational numbers.
^^I think you meant (ry)^t in that last line.
Joined: 12/28/2007
Posts: 235
Location: Japan, Sapporo
Warp wrote:
At some point I realized that the Cantor's diagonal argument technically speaking is a demonstration that the set of all possible infinite strings of digits is uncountable. (If we assumed that we can enumerate all possible infinite strings of digits, the argument shows that the assumption leads to a contradiction.)
Technically speaking that in itself doesn't yet prove that the set of reals is uncountable. We would still need to prove that the set of reals has the same size as the set of all possible infinite strings of digits.
I'm not completely sure that's trivial, given that some different strings of digits represent the same real number.
Decimal representation of reals is sometimes not unique: for example, 1.00... = 0.99999..., but Cantor's argument can avoid this ambiguity by choosing digits 1 or 2 when constructing a new real number from a countably-indexed list of reals.
Retired because of that deletion event.
Projects (WIP RIP): VIP3 all-exits "almost capeless yoshiless", VIP2 all-exits, TSRP2 "normal run"
We interrupt your smart people talks with a really basic, 8th grade, geometry question, but I was wondering and don't know the answer.
As far as rectangles go, I know that the most efficient use of space is a perfect square, since you get the most area for the same perimeter, i.e. 5*5 makes 25, but 6*4 only makes 24.
However, how does it look when you are looking at non-rectangular shapes. What about other polygons, circles or other, irregular shapes?
Is there any two-dimensional shape that can beat a square in terms of area efficiency?
The shape that can hold the largest area with any given perimeter or circumference is the circle. Generally speaking, the more sides you add to a regular polygon, given that the perimeter does not change, the larger the area that shape can hold.
Let's start with squares vs rectangles.
Let P be the value of the shape's perimeter, and x be the length of the shape. Thus, the length of the shape will be (1/2)*(P-2x).
This gives an area of ((1/2)*(P-2x))*x = A, which is equal to 1/2*Px - x^2. To maximize this, we take the derivative of A and set it equal to 0 to find our ideal values of x.
dA/dx = 1/2*P - 2x = 0.
This, 2x = 1/2*P, or x = P/4. So we can see that the maximum area comes from when x is exactly 1/4th of the perimeter, as in a square.
Compare to a circle:
The circumference of a circle is 2*pi*r. If we make that equal to the perimeter of our square, then the sides of the square will be x=(pi*r)/2 in length (since P = 4x), and it's area will be ((pi*r)/2)^2 = (pi^2 * r^2)/4, or rearranging it to compare to the area of a circle 1 * (pi * r^2), we get (pi/4) * (pi * r^2).
From this, it is clear that 1 > pi/4, and so the area of the circle is greater than the area of the square.
Which reminds me of the classic joke:
An architect, a physicist and a mathematician are given a 4-meters long rope and the task to enclose the maximum possible area of ground with it. The one who encloses the largest area wins.
The architect, being used to rectangular shapes, makes a square with the rope. The area of the square is 1 m2.
The physicist is smarter, so he makes a circle with the rope, as well as he can. The enclosed area is 4/pi, ie. about 1.27 m2.
The mathematician then takes the rope and lazily makes a nondescript shape with it. He doesn't even use the full length of the rope, making it cut itself somewhere. He the declares: "I win."
The others are puzzled. "What do you mean you win? Clearly your area is much smaller than mine" says the physicist.
The mathematician then steps inside the shape he made and says: "I define myself to be outside."
I'm sorry but I feel like I have to bump this one:
Archanfel wrote:
-Radiuses of all small circles = 1. Find radius of big circle.
FractalFusion wrote:
For the last question (pentagon and square arrangement of unit circles problem):
Let the center be the origin. Take a point where the inner circles touch and rotate the diagram so it is on the positive x-axis. Then the inner and outer circle in quadrant I touching the x-axis form the following diagram (not perfectly to scale):
Then x=tan 54° and so the distance from the origin to the center of the outer circle is sqrt(x2+4x+5)=sqrt((tan 54°)2+4(tan 54°)+5)
Therefore, the radius of the big circle (enclosing the outer circles) is one unit more; that is, sqrt((tan 54°)2+4(tan 54°)+5)+1. You can substitute tan 54°=φ/sqrt(3-φ) if you like (φ is the golden ratio (1+sqrt(5))/2), but I won't do that here. The number comes out to be about 4.521, close to Flip's estimate.
How can we show that the radius described in this solution actually goes through the center of the small outer circle? In other words, how can we be sure that the line that goes through the big circle's center and the small outer circle's center also goes through the point where both of these circles are tangent?
I agree with FractalFusion's solution and have successfully proved the above numerically, but I refuse to believe there isn't a simple way to prove it. I just can't see it...
Consider a small circle on the outer layer. The point on this which is the furthest distance from the origin, is clearly just going to be the one on the opposite side from where the origin was, IE in the same direction.
Now, to construct the large radius, we need to enclose all points on the outer circles, including the one furthest away; otherwise that bit would stick out and thus our large radius would not enclose it.
Hence the value of the large radius being the value of the furthest distance away, and since the point on the circle which is furthest distance is the one going in the same direction, we conclude that the radius of the large circle goes through the center of the smaller one.
Essay time.
Consider this statement:
lim(n→∞) sum(0, n) 1/n2 = 2
In other words,
1 + 1/2 + 1/4 + 1/8 + 1/16 + ... approaches the value 2 as the number of terms approaches infinity. This is rather a rather indisputable mathematical fact. The above is a true equality.
However, can we write it like this?
1 + 1/2 + 1/4 + 1/8 + 1/16 + ... = 2
This is a rather different statement. It is not a limit statement. It is not an expression saying that as more and more terms are added to the sum, said sum approaches the value 2. Instead, it's an expression that states that the sum of that series of infinite amount of terms is mathematically equal to 2. Not just that it approaches 2, but that it is 2. This is mathematically and philosophically a rather different proposition.
Although one could present philosophical objections to the statement (because the concept of having an infinite number of terms is not something that can just be taken as a self-evidently defined thing), it is nevertheless a pretty non-controversial and easy to accept convention. It is, after all, when we get down to it, a convention that mathematics has agreed to. It has been agreed that it is ok to have a sum with an infinite amount of terms, and that said sum can be mathematically equal to a given value. There are good reasons to accept this convention as completely valid.
But what happens if we take some more equivalent conventions, and apply them to infinite sums whose partial sums do not converge to a given value, but thanks to these agreed conventions nevertheless have an unambiguous unique value, which they are equal to? For example, it can be demonstrated that, using these conventions, this equality holds (and is unique):
1 + 2 + 4 + 8 + 16 + ... = -1
Obviously no partial sum of that series converges to -1 (or to any value at all). But we are not talking about partial sums. We are talking about an infinite sum. It is not the same thing.
Again, philosophical objections can be presented against considering the above equality valid. But are these objections, in principle, any different from the ones presented against the infinite sum of reciprocals of powers of two? (Again, we are not talking about a limit here, but about a literal sum with an infinite number of terms, which is not the same thing.)
Granted, more conventions need to be agreed on in order to arrive to that equality, but these conventions are not any less mathematically justified than the less-controversial one. And the end result is not arbitrary, but can be uniquely and unambiguously defined. (This is unlike those tricks that can be used to show contradictions like that "1=2" by using undefined operations which can yield any arbitrary value you want. In this case there is no arbitrariness.)
The more famous statement
1 + 2 + 3 + 4 + 5 + ... = -1/12
is a result of a few more similar conventions being agreed upon in mathematics. These conventions can be philosophically controversial, but not necessarily mathematically any more wrong than accepting that
1 + 1/2 + 1/4 + 1/8 + 1/16 + ... = 2
So, I suppose, it is a question of whether you accept these mathematical conventions on a philosophical level or not.
I'm sorry I can't answer your philosophical questions, I'm just here for the maths.
Warp wrote:
lim(n→∞) sum(0, n) 1/n2 = 2
In other words,
1 + 1/2 + 1/4 + 1/8 + 1/16 + ...
(I'll assume you meant (1/2)n up there)
Now, the former is a valid mathematical statement with a valid definition and rules deriving from it (such as, for example, adding or subtracting limits).
The latter, however, is something made up by someone who forgot to give a valid definition, meaning you can't really use maths on them.
Let's do it anyways.
I don't know how you were thinking about proving the 1 + 2 + 4 + 8 + 16 + ... = -1 one, but let me give an example how people usually do it.
But let's try both of them, anyways.
(1)
1 + 1/2 + 1/4 + 1/8 + 1/16 + ... = S
multiply by 2 and you get
2 + 1 + 1/2 + 1/4 + 1/8 + 1/16 + ... = 2S
now subract and you get
2 = 2S - S
2 = S
right?
(2)
1 + 2 + 4 + 8 + 16 + ... = T
2 + 4 + 8 + 16 + ... = 2T
1 = T - 2T
-1 = T
Surely if (1) works (and it's even mathematically valid) then (2) has to work, too, right?
Now, even if there are other ways to prove (2), there is one important thing to remember: We're giving values to limits.
The only reason why (1) works and gives us the correct value, is because of definitions and proven rules. For example, let (an) and (bn) be sequences:
lim(n→∞) an - lim(n→∞) bn = lim(n→∞) (an-bn)
This is what is basically being used in (1) and (2). But this only works when (an) and (bn) are convergent in the first place.
It might sound strange at first, that you're unable to subtract or add sums and retain equality, but we're dealing with infinite sums here.
To apply basic mathematical operations, you first have to prove that they work as expected.
If they don't, then you might screw up mathematics if you use them anyways.
Warning: Might glitch to creditsI will finish this ACE soon as possible
(or will I?)






















 -Radiuses of all small circles = 1. Find radius of big circle.
-Radiuses of all small circles = 1. Find radius of big circle.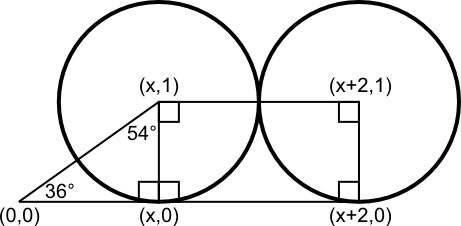 Then x=tan 54° and so the distance from the origin to the center of the outer circle is sqrt(x2+4x+5)=sqrt((tan 54°)2+4(tan 54°)+5)
Therefore, the radius of the big circle (enclosing the outer circles) is one unit more; that is, sqrt((tan 54°)2+4(tan 54°)+5)+1. You can substitute tan 54°=φ/sqrt(3-φ) if you like (φ is the golden ratio (1+sqrt(5))/2), but I won't do that here. The number comes out to be about 4.521, close to Flip's estimate.
Then x=tan 54° and so the distance from the origin to the center of the outer circle is sqrt(x2+4x+5)=sqrt((tan 54°)2+4(tan 54°)+5)
Therefore, the radius of the big circle (enclosing the outer circles) is one unit more; that is, sqrt((tan 54°)2+4(tan 54°)+5)+1. You can substitute tan 54°=φ/sqrt(3-φ) if you like (φ is the golden ratio (1+sqrt(5))/2), but I won't do that here. The number comes out to be about 4.521, close to Flip's estimate.














