Math Problem above my head:
Lets say you want 900 random samples, taken sequentially to have a rate of 80%, i.e. 1/5 comes out X, otherwise Y. Now, obviously, you could just assign a random number with a 1/5th probability. However, I vaguely remember from statistics class that you can readjust your probability function every time a new sample is produced, to adjust the probability that it actually will reach a near perfect 80% at the end of the 900 samples. In other words, as opposed to a uniform probability, you force it to use apriori information to determine the next probability.
I don't know know if that made sense.
Sage advice from a friend of Jim: So put your tinfoil hat back in the closet, open your eyes to the truth, and realize that the government is in fact causing austismal cancer with it's 9/11 fluoride vaccinations of your water supply.
So basically you're looking at something like this:
odds = .2
numX = 0
for i in [0, 900):
if rand() < odds:
numX++
remainingSamples = 900 - i
target = .2 * 900 - numX
odds = target / remainingSamples
I think that should work. Each iteration, you figure out what odds you need so that by the end, 20% of your samples have come out X, based on how many X you've gotten so far and how many iterations you have left to go.
EDIT: yeah, this looks like it works. Pretty consistently generates a 20% success rate, occasionally 1 below, never further from the target than that.
Pyrel - an open-source rewrite of the Angband roguelike game in Python.
Lets say you want 900 random samples, taken sequentially to have a rate of 80%, i.e. 1/5 comes out X, otherwise Y. Now, obviously, you could just assign a random number with a 1/5th probability. However, I vaguely remember from statistics class that you can readjust your probability function every time a new sample is produced, to adjust the probability that it actually will reach a near perfect 80% at the end of the 900 samples. In other words, as opposed to a uniform probability, you force it to use apriori information to determine the next probability.
I don't think I understood this. If you're able to manipulate the probability function at will, couldn't you simply assign it to 1 if you have less than 180 X samples and 0 otherwise? Or are there bounds for the probability of X and Y?
Joined: 11/30/2008
Posts: 650
Location: a little city in the middle of nowhere
I don't think I understood this. If you're able to manipulate the probability function at will, couldn't you simply assign it to 1 if you have less than 180 X samples and 0 otherwise? Or are there bounds for the probability of X and Y?
There's no randomness in that algorithm. you would always get the same result: 180 x's followed by 720 y's. He wants a random sample that remains as close as possible to 80% in the final distribution.
I think a better way to do this, that will always succeed is consider a field of 900 Y's, now generate a number between 1 and 900. Replace the Y with an X at that position, now ignore that position for further iterations of a loop, generate a number between 1 and 899. place an X at that positon, and so on and so forth. Do this until the number of X's = 1/5th of 900.
I'm pretty sure this produces a fair randomness sample, it will produce any distribution of 180 x's intersperced with 720 Y's with equal probability. ( 1/(900C180) )
Joined: 11/30/2008
Posts: 650
Location: a little city in the middle of nowhere
Or take a list of 180 x's and 720 y's and shuffle it. There's plenty of fast algorithms for that on the webz.
Sure there may be a lot of algorithm's on "the webz" but if you use one of them, you can't be sure it's unbiased. Plus, it's not like my algorithm would take more than a second anyway. Maybe if you're dealing with hundreds of thousands of numbers, then that might be a different story, but I'm almost sure there my algorithm is O(n) if done right, so it's pretty fast no matter how many numbers you want.
I don't think I understood this. If you're able to manipulate the probability function at will, couldn't you simply assign it to 1 if you have less than 180 X samples and 0 otherwise? Or are there bounds for the probability of X and Y?
There's no randomness in that algorithm. you would always get the same result: 180 x's followed by 720 y's. He wants a random sample that remains as close as possible to 80% in the final distribution.
So, is the order supposed to matter here? If so, the problem is equivalent to shuffling a deck.
As it can be seen from my other post, it's always possible to obtain the exact probability in the end as long as you get 180 1's and 720 0's in the probability function. So, suppose you have a list of 180 1's and 720 0's and shuffle it. Now, when you're going to grab the i-th sample, set the probability function to the i-th number, and you have 180 X's and 720 Y's in randomized order.
Most of the time, I just call a sorting algorithm with a randomized function like rand()%2 instead of a comparison when I want to shuffle an array.
My guess, though, is that Dark Kobold was looking for something like this: suppose you have to take 900 samples sequentially, the probability of it being of type X is p(X) and can be changed. How would you manipulate it so that you have the highest chance of being close to 20% X after each sample is taken (not only at the end)?
If you have x X's and y Y's, your current ratio is x/(x+y), if you take an X, it goes to (x+1)/(x+y+1), if you don't, it's x/(x+y+1). So, you want your next ratio to be 1/5, your expected ratio can be defined in terms of the probability function:
(x+1)*p(X)/(x+y+1) + x*(1-p(X))/(x+y+1) = 1/5
Solving the equation, we get p(X) = (y-4x+1)/5 . Obviously, 0<=p(X)<=1, so in the case it gets negative, pick 0, if it gets larger than 1, pick 1.
There are a lot of fast algorithms which will create pseudo random input, but it's extremely hard to create a shuffling algorithm that will give an even probability for all of the distinct possibilities.
Oh come on, Fisher-Yates is not that hard; it's not like implementing cryptography or mersenne twister or something like that.
Joined: 11/30/2008
Posts: 650
Location: a little city in the middle of nowhere
Hmm, when I think about it, Fisher-Yates is probably the algorithm Darkkobold wants. You start off with a list of 180 X's and 720 Y's and randomly shoose one out of that list to be the next number in the sequence. It works because if you strike out an X, it will change the probability of getting an X for the next roll, and when you get to the end, there will be either 100% chance of getting Y or X. This algorithm is guraranteed to get 180 X's and 720 Y's and also guarantees equal probability for all combinations.
There are a lot of fast algorithms which will create pseudo random input, but it's extremely hard to create a shuffling algorithm that will give an even probability for all of the distinct possibilities.
I've once developed an algorithm for converting a random number from 1-n, with n being the number of possible random distributions, to the xth possible random distribution. Maybe it'd be useful here? If it is, then I'll dig it up. It should be completely unbiased.
Oh come on, Fisher-Yates is not that hard; it's not like implementing cryptography or mersenne twister or something like that.
It's also handy in that you don't need to shuffle the entire list if you only need a smaller amount of random elements.
In other words, if you need eg. 100 non-repeating random numbers in the range 0-200, you can put the values 0-200 in the array and run the algorithm for the first 100 elements only (rather than the entire array) and you will get your 100 non-repeating random numbers from that range (with even probability).
My turn!
1) TASBALL is a game of three players. In each match, the winner scores a points, the player at the second place scores b points and the last one scores c points, where a > b > c are positive integers. A certain day, Alice, Bob and Charlie decide to play TASBALL and after some matches, their total points were:
Alice: 20
Bob: 10
Charlie: 9
It's known that Bob won the second match. Find the amount of points each player scored in each match.
2) Consider the sets P1, P2, S1 and S2 such that , and .
Prove that .
3) A sequence of natural numbers is "pretty" if, for every consecutive terms ai, ai+1 in the sequence, |ai - ai+1| <= 1 and no number other than 1, 2, 3, 4 or 5 appears in the sequence.
For example, (3, 4, 4, 5, 4, 3, 2, 2, 3, 2) is a pretty sequence.
How many pretty sequences of 2011 numbers exist?
1) The total number of points is 39 = 3*13. This means that there were either 13 matches with 3 points/match or 3 matches with 13 points/match. The former is impossible, since a+b+c must be at least 6.
Bob won the second match, and he got fewer points than he would if he got in second and third in the other two matches. Hence, he got in third in the other two matches, and b-c=3. Thus b is at least 4, and c is at least 1.
Charlie must therefore have gotten in at least second place in the first and third matches, and at least third place in the second match. This gives a minimum of 4+1+4=9 points, which is exactly what he got. Hence c=1, b=4, and a=8.
The results are as follows:
Alice: 8+4+8=20 points.
Bob: 1+8+1=10 points.
Charlie: 4+1+4=9 points.
2) Let x be an element of the intersection of S1 and S2. By the third statement, x is either in P1 or in P2. If x is in P1, then it is in P1 and S2, and hence P2. If x is in P2, then it is in P2 and S1, and hence P1. Thus, either way, x must be in both P1 and P2, and this proves the result.
calculated using:
[code pretty_sequence.cpp]// g++ -lgmpxx -lgmp pretty_sequence.cpp
#include <iostream>
#include <gmpxx.h>
using namespace std;
const int n = 2011;
int main()
{
mpz_class p[n+1][3]; // p[n] = P(n,i+1)
for (int i=0;i<3;i++)
p[1] = 1;
for (int i=2;i<=n;i++)
{
p[0] = p[i-1][0] + p[i-1][1];
p[1] = p[0] + p[i-1][2];
p[2] = 2*p[i-1][1] + p[i-1][2];
mpz_class total = 2*p[0] + 2*p[1] + p[2];
cout << total << " pretty sequences of length " << i << endl;
}
return 0;
}[/code]
(There's no need to keep the whole array in memory; two rows would be enough. But there's no point in optimizing for memory when it runs without swapping.)
You choose n = 2011, so I guess you have some specific use of this sequence in mind. Which is it?
2011 is just an arbitrarily high number to make this approach impossible to anyone who does not have access to a computer.
I want an expression that will yield P(2011).
My guess, though, is that Dark Kobold was looking for something like this: suppose you have to take 900 samples sequentially, the probability of it being of type X is p(X) and can be changed. How would you manipulate it so that you have the highest chance of being close to 20% X after each sample is taken (not only at the end)?
If you have x X's and y Y's, your current ratio is x/(x+y), if you take an X, it goes to (x+1)/(x+y+1), if you don't, it's x/(x+y+1). So, you want your next ratio to be 1/5, your expected ratio can be defined in terms of the probability function:
(x+1)*p(X)/(x+y+1) + x*(1-p(X))/(x+y+1) = 1/5
Solving the equation, we get p(X) = (y-4x+1)/5 . Obviously, 0<=p(X)<=1, so in the case it gets negative, pick 0, if it gets larger than 1, pick 1.
Thanks, I'm pretty sure this is exactly what I was looking for!
Sage advice from a friend of Jim: So put your tinfoil hat back in the closet, open your eyes to the truth, and realize that the government is in fact causing austismal cancer with it's 9/11 fluoride vaccinations of your water supply.
Thanks, I'm pretty sure this is exactly what I was looking for!
You're welcome. I'm glad one of the things I wrote solved your problem :D
3) (without programming)
I'm gonna use Tub's notation here. As was pointed out by him:
P(n,1) = P(n-1,1) + P(n-1,2)
P(n,2) = P(n-1,1) + P(n-1,2) + P(n-1,3)
P(n,3) = 2*P(n-1,2) + P(n-1,3)
This is a system of linear recurrences. Let's put it in matricial form. Let Vn denote the vector [ P(n,1) P(n,2) P(n,3) ]T and:
[ 1 1 0 ]
[ 1 1 1 ] = M, Vn = M Vn-1 and P(n) = [ 2 2 1 ] Vn
[ 0 2 1 ]
It can be proved by PMI that Vn = Mn-1 V1 . I've reduced the problem to the exponentiation of a matrix. Diagonalization comes to mind immediately.
The characteristic equation of M is (1-t)3 - 3(1-t) = 0, which gives the eigenvalues t=1-sqrt(3), t=1 and t=1+sqrt(3). Solving three linear systems, we get their respective eigenvectors, which are (-sqrt(3)/3 , 1 , -2sqrt(3)/3) , (1,0,-1) and (sqrt(3)/3 , 1 , 2sqrt(3)/3).
So, if A denotes the matrix that has the eigenvectors at its columns, we need to find A-1. There are plenty of ways to compute the inverse, my favorite for 3x3 is 1/det times the transposed cofactor matrix (I always mess up on gaussian elimination). This way, we have M = A D A-1 , where D is a diagonal matrix formed by the eigenvalues in the order their respective eigenvectors were put in A.
More notably, we have Mn-1 = A Dn-1 A-1 . And a diagonal matrix is easy to exponentiate, because we just need to exponentiate the numbers in the main diagonal individually. We're also a little lucky, because one of them is 1, that is the same when elevated to any number. After all, we have this:
We can do less operations by using the associative property, after all computation is done, we finally get to the general term:
Thus, the amount of pretty sequences of length 2011 is given by substituting n=2011 in the above formula.
If you were to allow programming to find the decimal digits of P(n), this can be done in O (log n) operations with no precision loss by an application of a cross function. It will use multiplications, which are slower than additions, but if GMP uses Karatsuba multiplication or its variants, it will be done quite efficiently.
I haven't tested this much, but it should work, for 2011 it seems to answer the same thing as Tub's program.
For those unfamiliar with the game, Mega Man 2 starts with 8 stages that can be completed in any order, and 3 of them yield Items; if you choose the stages randomly, by the completion of which stage are you more likely than not to have at least one of the three Items?
Pretty easy.
after stage 1: 3/8 of having item, 5/8 of not. total change = 37.5%
after stage 2, without item: 3/7 chance of having item, 4/7 of not. total chance = 3/8 + (5/8)*(3/7) = 64.29%
Joined: 11/30/2008
Posts: 650
Location: a little city in the middle of nowhere
This is a fairly simple question. On the first stage you have a 3/8 chance of getting an item. On the second stage, you have a (3/8 + 3/7*5/8) chance of having an item (36/56, or 64%) so by the second stage, you are more likely to have an item than not.
A general solution to this problem is as follows: let's say you have x stages and y items. The probability of having an item by stage z is 1 - ((x-y)Pz)/(xPz). (i.e the compliment of the probability of not getting an item.) Probably can be simplified.
EDIT: Damn, too late.
A general solution to this problem is as follows: let's say you have x stages and y items. The probability of having an item by stage z is 1 - ((x-y)Pz)/(xCz).
By xCz you mean x! / ((x-z)! z!) and by (x-y)Pz , (x-y)! / z! ?
Shouldn't the answer be 1 - ((x-y)Cz)/(xCz) ?
Joined: 11/30/2008
Posts: 650
Location: a little city in the middle of nowhere
by (x-y)Pz I mean (x-y)!/(x-y-z)!.
You should know that P(e) = n(e)/n(s) where e is not getting an item. n(s) will then be xPz and n(e) will be (x-y)Pz, so they should actually both be P not C. But of course, 1 - ((x-y)Cz)/(xCz) also works, because the only difference is to add the z! term to both the numerator and denominator.
So yes, you're right.
Interesting, I just thought: I have to pick z stages out of x. To see if I have an item or not, the order doesn't matter, so I can think of only combinations. I have no item if I picked a combination of x stages that's also a combination of x-y no-item stages.
There are xCz of the former and (x-y)Cz of the latter, the probability follows right after.
I expected someone to get tripped up by saying "stage 3, because that's when you'd have a 50/50 chance of getting an Item"; similarly I'll try to figure out the expected stages by which 2 Items and all 3 Items would have been obtained...
2 Items
2: 3/8*2/7=3/28, about 11%
3: 3/28+2*5/8*3/7*2/6=2/7, about 29%
4: 2/7+3*5/8*4/7*3/6*2/5=1/2, 50%
all 3 Items
3: 3/8*2/7*1/6=1/56, about 2%
4: 1/56+3*5/8*3/7*2/6*1/5=1/14, about 7%
5: 1/14+6*5/8*4/7*3/6*2/5*1/4=5/28, about 18%
6: 5/28+10*5/8*4/7*3/6*3/5*2/4*1/3=5/14, about 36%
7: 5/14+15*5/8*4/7*3/6*2/5*3/4*2/3*1/2=35/56, 62.5%
more generally...
If there are M>0 items scattered among N>M stages, the probability of having found at least K in [0,M] of them by stage J in [K,N] is
SUM(C(I-1,K-1)*P(N-M,I-K)*K!/P(N,N-I),I,K,J)











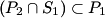 ,
, 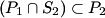 and
and 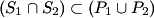 .
Prove that
.
Prove that 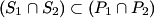 .
3) A sequence of natural numbers is "pretty" if, for every consecutive terms ai, ai+1 in the sequence, |ai - ai+1| <= 1 and no number other than 1, 2, 3, 4 or 5 appears in the sequence.
For example, (3, 4, 4, 5, 4, 3, 2, 2, 3, 2) is a pretty sequence.
How many pretty sequences of 2011 numbers exist?
.
3) A sequence of natural numbers is "pretty" if, for every consecutive terms ai, ai+1 in the sequence, |ai - ai+1| <= 1 and no number other than 1, 2, 3, 4 or 5 appears in the sequence.
For example, (3, 4, 4, 5, 4, 3, 2, 2, 3, 2) is a pretty sequence.
How many pretty sequences of 2011 numbers exist?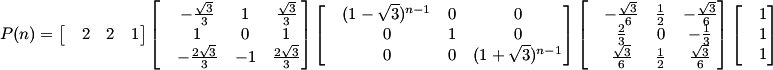 We can do less operations by using the associative property, after all computation is done, we finally get to the general term:
We can do less operations by using the associative property, after all computation is done, we finally get to the general term:
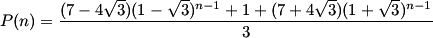 Thus, the amount of pretty sequences of length 2011 is given by substituting n=2011 in the above formula.
If you were to allow programming to find the decimal digits of P(n), this can be done in O (log n) operations with no precision loss by an application of a cross function. It will use multiplications, which are slower than additions, but if GMP uses Karatsuba multiplication or its variants, it will be done quite efficiently.
I haven't tested
Thus, the amount of pretty sequences of length 2011 is given by substituting n=2011 in the above formula.
If you were to allow programming to find the decimal digits of P(n), this can be done in O (log n) operations with no precision loss by an application of a cross function. It will use multiplications, which are slower than additions, but if GMP uses Karatsuba multiplication or its variants, it will be done quite efficiently.
I haven't tested 