Experienced Forum User, Published Author, Player
(42)
Joined: 12/27/2008
Posts: 873
Location: Germany
I managed to find the O(v3) algorithm in a combinatorial optimization book I never knew I had, lol. It's much more elegant than the one I was thinking. It manages to create the entire forest, blossoms, check for distances and lift the path only by applying labels to the nodes. The length of the code is still big, though...
After around 250 lines, I got Accepted, it seems I smashed the time limit. Their test cases must not have been as bad as I thought, maybe the idea was to really use the O(v4) version xD.
I tried to make a commented version if anyone wants to see. I don't want to post accepted code, so I changed the way the graph is read and modified it to output the maximum matching. Most of it is still copypasted from the other one, so there are still some ugly things like code duplication and global variables.
Warp wrote:
That reminds me of the time when I had to make programs for manipulating graphs as my payjob. I learned quite a lot about graphs back then (and have forgotten most of it since).
For example, checking if two graphs are isomorphic is an NP problem. (Two graphs are isomorphic if you can rearrange one of them so that it becomes identical to the other. That might at first sound like a trivial problem, but it's, in fact, an extremely hard one.)
Curiously, determining if two graphs are strongly bisimilar is a polynomial-time problem, even though the problem sounds very similar to the isomorphism problem. (Two graphs with named arcs are strongly bisimilar if all the named paths in one graph exist in the other, and vice-versa.)
Strong bisimilarity happens to be a much more useful comparison of graphs than isomorphism, so it's lucky that it's an easy problem.
I remember that when I first heard of Travelling Salesman, I thought it would be an easy problem, since FW could find all pairs shortest path quite efficiently, shortly after I came to know it's NP-hard... I also had trouble understanding why 2-SAT is solved in polynomial time and 3-SAT (which is awfully similar) is NP-complete.
Experienced Forum User, Published Author, Player
(42)
Joined: 12/27/2008
Posts: 873
Location: Germany
DarkKobold wrote:
Thanks, I'm pretty sure this is exactly what I was looking for!
You're welcome. I'm glad one of the things I wrote solved your problem :D
3) (without programming)
I'm gonna use Tub's notation here. As was pointed out by him:
P(n,1) = P(n-1,1) + P(n-1,2)
P(n,2) = P(n-1,1) + P(n-1,2) + P(n-1,3)
P(n,3) = 2*P(n-1,2) + P(n-1,3)
This is a system of linear recurrences. Let's put it in matricial form. Let Vn denote the vector [ P(n,1) P(n,2) P(n,3) ]T and:
[ 1 1 0 ]
[ 1 1 1 ] = M, Vn = M Vn-1 and P(n) = [ 2 2 1 ] Vn
[ 0 2 1 ]
It can be proved by PMI that Vn = Mn-1 V1 . I've reduced the problem to the exponentiation of a matrix. Diagonalization comes to mind immediately.
The characteristic equation of M is (1-t)3 - 3(1-t) = 0, which gives the eigenvalues t=1-sqrt(3), t=1 and t=1+sqrt(3). Solving three linear systems, we get their respective eigenvectors, which are (-sqrt(3)/3 , 1 , -2sqrt(3)/3) , (1,0,-1) and (sqrt(3)/3 , 1 , 2sqrt(3)/3).
So, if A denotes the matrix that has the eigenvectors at its columns, we need to find A-1. There are plenty of ways to compute the inverse, my favorite for 3x3 is 1/det times the transposed cofactor matrix (I always mess up on gaussian elimination). This way, we have M = A D A-1 , where D is a diagonal matrix formed by the eigenvalues in the order their respective eigenvectors were put in A.
More notably, we have Mn-1 = A Dn-1 A-1 . And a diagonal matrix is easy to exponentiate, because we just need to exponentiate the numbers in the main diagonal individually. We're also a little lucky, because one of them is 1, that is the same when elevated to any number. After all, we have this:
We can do less operations by using the associative property, after all computation is done, we finally get to the general term:
Thus, the amount of pretty sequences of length 2011 is given by substituting n=2011 in the above formula.
If you were to allow programming to find the decimal digits of P(n), this can be done in O (log n) operations with no precision loss by an application of a cross function. It will use multiplications, which are slower than additions, but if GMP uses Karatsuba multiplication or its variants, it will be done quite efficiently.
I haven't tested this much, but it should work, for 2011 it seems to answer the same thing as Tub's program.
Experienced Forum User, Published Author, Player
(42)
Joined: 12/27/2008
Posts: 873
Location: Germany
2011 is just an arbitrarily high number to make this approach impossible to anyone who does not have access to a computer.
I want an expression that will yield P(2011).
Experienced Forum User, Published Author, Player
(42)
Joined: 12/27/2008
Posts: 873
Location: Germany
Well, lately, I've been trying to solve this programming problem. Yeah, it's in Portuguese, but you can ignore the description. It'll give you a set of (possibly nonbipartite) graphs in the following way, first, the number of graphs, then for each graph, the number of vertices followed by one line for each vertex, containing its degree and the vertices it's linked to.
You should output "pair programming" if a perfect matching exists in the graph and "extreme programming" if it doesn't.
This is an old problem, from way back when they had the annoying habit of creating difficulty by requiring the use of "obscure" algorithms (and seeing from how often they have to rejudge these kind of problems, possibly even the examiners didn't know what they were doing, in fact, most people who passed this one used a transformation to a bipartite graph that doesn't always work, but the judge failed to eliminate). Anyway, AFAIK the only way to determine if a perfect matching exists is to actually compute the maximum matching and see if it covers all nodes. The most common algorithm for this is due to Edmonds, despite being a pain to implement, it's still the easiest one. However, it's O(v4), and the n<=100 restriction in the problem will only allow O(v3) or faster to pass. Well, maybe O(v4) could pass if one were to minimize function calls, instructions and use static variables, but since the algorithm is complicated, the constants hidden by the O notation are probably large.
Knowing this, I searched the internet for the faster versions of the algorithm, but always ended up in a page I needed to pay to have access to the paper. The only thing I got was a Fortran code implementing the O(sqrt(v)*e) version, which had over 1500 lines of code. This is a bit too much. I know that Edmonds's algorithm can be implemented in O(v3), and will be satisfied if I manage to do that.
Still, the problem is that I can't find any clues about this implementation in the web. I'm 99% sure that the improvement comes from optimizing blossom contraction and path lifting. In fact, I'm close to doing that, by using the original graph all the time, using auxiliary arrays to make the algorithm "think" the blossom was contracted and work. I might be able to do it if I find a way to deal with blossom within a blossom problems, but the method I'm thinking may be over-complicated. Anyway, I'm asking if anyone knows where I can find this algorithm, I know I'd have better luck asking at the problem site's forum, but not many people go there.
Experienced Forum User, Published Author, Player
(42)
Joined: 12/27/2008
Posts: 873
Location: Germany
My turn!
1) TASBALL is a game of three players. In each match, the winner scores a points, the player at the second place scores b points and the last one scores c points, where a > b > c are positive integers. A certain day, Alice, Bob and Charlie decide to play TASBALL and after some matches, their total points were:
Alice: 20
Bob: 10
Charlie: 9
It's known that Bob won the second match. Find the amount of points each player scored in each match.
2) Consider the sets P1, P2, S1 and S2 such that , and .
Prove that .
3) A sequence of natural numbers is "pretty" if, for every consecutive terms ai, ai+1 in the sequence, |ai - ai+1| <= 1 and no number other than 1, 2, 3, 4 or 5 appears in the sequence.
For example, (3, 4, 4, 5, 4, 3, 2, 2, 3, 2) is a pretty sequence.
How many pretty sequences of 2011 numbers exist?
Experienced Forum User, Published Author, Player
(42)
Joined: 12/27/2008
Posts: 873
Location: Germany
andymac wrote:
I don't think I understood this. If you're able to manipulate the probability function at will, couldn't you simply assign it to 1 if you have less than 180 X samples and 0 otherwise? Or are there bounds for the probability of X and Y?
There's no randomness in that algorithm. you would always get the same result: 180 x's followed by 720 y's. He wants a random sample that remains as close as possible to 80% in the final distribution.
So, is the order supposed to matter here? If so, the problem is equivalent to shuffling a deck.
As it can be seen from my other post, it's always possible to obtain the exact probability in the end as long as you get 180 1's and 720 0's in the probability function. So, suppose you have a list of 180 1's and 720 0's and shuffle it. Now, when you're going to grab the i-th sample, set the probability function to the i-th number, and you have 180 X's and 720 Y's in randomized order.
Most of the time, I just call a sorting algorithm with a randomized function like rand()%2 instead of a comparison when I want to shuffle an array.
My guess, though, is that Dark Kobold was looking for something like this: suppose you have to take 900 samples sequentially, the probability of it being of type X is p(X) and can be changed. How would you manipulate it so that you have the highest chance of being close to 20% X after each sample is taken (not only at the end)?
If you have x X's and y Y's, your current ratio is x/(x+y), if you take an X, it goes to (x+1)/(x+y+1), if you don't, it's x/(x+y+1). So, you want your next ratio to be 1/5, your expected ratio can be defined in terms of the probability function:
(x+1)*p(X)/(x+y+1) + x*(1-p(X))/(x+y+1) = 1/5
Solving the equation, we get p(X) = (y-4x+1)/5 . Obviously, 0<=p(X)<=1, so in the case it gets negative, pick 0, if it gets larger than 1, pick 1.
Experienced Forum User, Published Author, Player
(42)
Joined: 12/27/2008
Posts: 873
Location: Germany
DarkKobold wrote:
Lets say you want 900 random samples, taken sequentially to have a rate of 80%, i.e. 1/5 comes out X, otherwise Y. Now, obviously, you could just assign a random number with a 1/5th probability. However, I vaguely remember from statistics class that you can readjust your probability function every time a new sample is produced, to adjust the probability that it actually will reach a near perfect 80% at the end of the 900 samples. In other words, as opposed to a uniform probability, you force it to use apriori information to determine the next probability.
I don't think I understood this. If you're able to manipulate the probability function at will, couldn't you simply assign it to 1 if you have less than 180 X samples and 0 otherwise? Or are there bounds for the probability of X and Y?
Experienced Forum User, Published Author, Player
(42)
Joined: 12/27/2008
Posts: 873
Location: Germany
Actually, the naive recursive solution transforms the problem in O(2n). The similar iterative/dynamic programming approach does it in O(n), but it can be solved in O(log n), like my code does.
Also, Derakon, you don't need to do N multiplications to exponentiate a number. For example, a27 = a16 * a8 * a2 * a. And a16 can be calculated by (((a2)2)2)2. The others are found at each iteration, so you'll need only O(log n) operations. Using the formula is just the same as exponentiating the diagonalized matrix, but since it will no longer be integral, there'll be some annoying precision errors.
Enough talking about Fibonacci. I guess I understood the problem wrong, at first, I thought it was about manipulating a function to which the programmer has no access. If it's about general solutions to speed up recursive algorithms, I think it depends on the problem. There are many ways to improve recursions, ranging from linear algebra, dynamic programming, game theory and even number theory, so it's pretty hard to come up with a generic approach.
Experienced Forum User, Published Author, Player
(42)
Joined: 12/27/2008
Posts: 873
Location: Germany
Doing this kind of wrapping seems very complicated. I tried to do something like that some time ago, to find out how many times std::sort() in C++ calls itself, but couldn't get anything.
I imagine it's possible if you were to watch the execution stack and replace the original function with the wrapped one when it gets on top of the stack, though I have no idea how to do that.
This is a bit out of subject, but memoization may not be required to efficiently evaluate Fibonacci numbers (and any other linear recurrence for that matter). Though it is still the best option if you want to find all of them, if you want only one, you can do it in logarithmic complexity using matrix exponentiation:
Language: C++
#include <iostream>
using namespace std;
struct mat{
unsigned long long m[2][2];
};
mat ident,fibMat;
mat operator* (mat a, mat b){
mat c;
c.m[0][0]=a.m[0][0]*b.m[0][0]+a.m[0][1]*b.m[1][0];
c.m[0][1]=a.m[0][0]*b.m[0][1]+a.m[0][1]*b.m[1][1];
c.m[1][0]=a.m[1][0]*b.m[0][0]+a.m[1][1]*b.m[1][0];
c.m[1][1]=a.m[1][0]*b.m[0][1]+a.m[1][1]*b.m[1][1];
return c;
}
mat pow (mat a, int n){
if (n==0) return ident;
if (n==1) return a;
if (n==2) return a*a;
return pow(pow(a,n/2),2)*pow(a,n%2);
}
unsigned long long fib (int n){
mat p;
if (n==0) return 0;
p=pow(fibMat,n-1);
return p.m[0][0];
}
int main(){
int n;
ident.m[0][0]=ident.m[1][1]=1;
ident.m[1][0]=ident.m[0][1]=0;
fibMat.m[0][0]=fibMat.m[0][1]=fibMat.m[1][0]=1;
fibMat.m[1][1]=0;
cin>>n;
cout<<fib(n);
return 0;
}
This can answer fast even ridiculously big stuff, like fib(1010000), though it will obviously overflow. Another option is to diagonalize the matrix, which is almost the same as using the formula for the general term, but it'll deal with some precision errors.
Experienced Forum User, Published Author, Player
(42)
Joined: 12/27/2008
Posts: 873
Location: Germany
petrie911 wrote:
I must say, I'm surprised that it's faster to catch Mewtwo from the Unknown Dungeon rather than to glitch him. Especially because Mewtwo is an option for the Missingno. Glitch.
Other pokemon are also an option for the Missingno. glitch . The difference is that, while Mewtwo is hard to get, version exclusive/one-time event pokemon are impossible to get without glitching. There are more than 10 pokemon that have very high IDs that are caught much easier with the Old Man glitch, and we can only have three of them. It's better to glitch the impossible than to glitch the hard one.
Seadra and Hypno take some significant amount of time to RC and having to evolve an extra Abra, like Mukki said, make going to Unknown Dungeon a viable option.
There are three ways of getting high-ID pokemon:
* Get a "fading experience" pokemon to level 100 with the right stats and let Ditto Transform into it. This is very slow, it requires one trainer battle and one wild battle for each L100 pokemon you use.
* Use the Old Man glitch. The fastest, but can only be used for three pokemon.
* Manipulate the high-level pokemon from the Old Man to have stats that will generate other hard pokemon. This is the method we're using, it's still slow, because it needs a lecture from the Old Man. In my four hour run, I did this seven times. Most of our improvement now comes from optimizing this part. Mukki and I managed to get this done with only three repetitions, two were taken out by cloning Eevee, one with an encounter that's very hard to manipulate, and other by using a Chansey at Unknown Dungeon.
So, overall, Unknown Dungeon is better because it avoids some leveling and is more friendly to other pokemon. For example, if we were to get Mewtwo from the Old Man, instead of Squirtle, we'd never visit UD, but would perform method #3 more times, use 20 more RCs for other pokemon and to get Squirtle to Blastoise, we'd need more 29 (L1-100 is not an option, it'll be stuck at Wartortle).
This is one of the reasons that this run is very hard to plan. Most of the time, when you optimize one species, you mess up others so you have to compare the gain-loss. The problem is probably NP-complete.
Experienced Forum User, Published Author, Player
(42)
Joined: 12/27/2008
Posts: 873
Location: Germany
Nobody was interested in the above question.
It was actually the simplest proof I know for Cardano's formula that I tried putting into a question.
(a) Elevating both sides of the equation to the cube we get: y3 = x1 + x2 + 3(x1x2)1/3(x11/3+x21/3), which can also be written as: y3 = S + 3 P1/3 y . Therefore, the polynomial Q(y) = y3 - 3 P1/3 y - S is the answer.
(b) Substituting x = y + t:
F(y+t) = y3 + (a+3t)y2 + (b+2at+3t2)y + (c+bt+at2+t3)
It's easy to see that t= -a/3 eliminates y2's coefficient.
(c) As you can see, this cubic doesn't admit rational roots, so we have to solve it by Cardano's method. It gets really big, I won't do it because I'm lazy leave it as an exercise for the reader. The process is: using (a), you can express a root of the equation in terms of the roots of a quadratic function if its coefficient for the quadratic term is zero. The equation doesn't satisfy this, but we can get rid of the coefficient using (b). After the first root is found, we can use Briot-Ruffini's algorithm to reduce it to a quadratic equation.
Additionally, (c) should also discourage you from using this method, since many times it doesn't produce useful results. For example, if one were to calculate cos 20º with cos 60º = 4 cos320º - 3 cos 20º or 4x3 - 3x - 1/2 = 0 , he would get:
cos 20º = (1/16 + i * sqrt(3)/16)1/3 + (1/16 - i * sqrt(3)/16)1/3
That doesn't tell much about cos 20º, because it has complex numbers. It can actually be demonstrated that any finite expression with radicals for cos 20º must involve complex numbers with non-zero imaginary part.
Experienced Forum User, Published Author, Player
(42)
Joined: 12/27/2008
Posts: 873
Location: Germany
I was expecting a Randper Kombat run to be submitted. This one was quite good, the amazing display of combos made it a pleasant watch. Personally, I turn my head away every time you miss a move, I really don't understand why this is done. There were also some glitches I'd like to see that weren't present, but that's a matter of the author's taste. Additionally, the small experience I had TASing this game indicated that the RNG can be manipulated easily, so I have to doubt if taking damage was mandatory.
That being said, this run is very cruel to opponents and has a much better pace than the other MK runs submitted, so it deserves a (somewhat weak) Yes vote.
Experienced Forum User, Published Author, Player
(42)
Joined: 12/27/2008
Posts: 873
Location: Germany
^
|
|
|
What he said. I'm not sure if there's something for SRAM specification in GBA ROMs, but surely, starting it up with the wrong save settings shouldn't stop the game from loading.
Last time I checked, newer versions of VBA could start the ROM with Flash 64K (the game would be unable to save though). With VBA 1.8, this issue was removed. The rerecording branch, however, started from an older version, so we have to get the correct settings manually.
Experienced Forum User, Published Author, Player
(42)
Joined: 12/27/2008
Posts: 873
Location: Germany
I had a brief overview of the glitches used here while this was still on the works, it was fun to see another game with a hole punched open in RAM, I'm rushed at the moment and can't watch it, but I expect this to be awesome. Will watch it later when I can safely add a Yes vote to the poll.
Experienced Forum User, Published Author, Player
(42)
Joined: 12/27/2008
Posts: 873
Location: Germany
@Tub:
In a real contest, there's no bonus for faster codes, so we usually don't care about optimizing it to death. The bonus comes from the time of your submission, meaning that someone who submits an accepted code in less time has the advantage. Each WA, TLE (time limit exceeded) or other rejected codes take a 20-minute penalty.
Aside from that, the time limit and the greatest value for input are usually set to allow algorithms with sub-optimal implementation of the right complexity to pass and reject others with higher complexity, even if coded well. This problem was an exception, the limits were unexpectedly generous.
It's also interesting to see that two solutions completely different theoretically end up doing the same thing. The LIS approach is very interesting. For the special case d=2, this problem can be solved in O(n log n), you might want to check it out.
@Warp:
I prefer it the other way because it gives me a better idea of the time it'll take. For example, when d is a lot larger than n, the part which will cost more is O (n d log d). It may be notation abuse, but...
If anyone else is interested in problems like that, there's a lot more at UVa, I just passed 104: Arbitrage, also a very interesting problem.
Experienced Forum User, Published Author, Player
(42)
Joined: 12/27/2008
Posts: 873
Location: Germany
Ah, OK. I didn't understand your idea, it should work. I'll submit it later.
EDIT 2: I got WA, and I know why. The sorting method for the boxes needs to be modified a little. Your method will only work if box i doesn't nest box j for any i>j. To guarantee this, comparing just their largest dimensions won't suffice. If their largest dimension happens to be equal, you must move to the second largest, in case of tying again, to the third and so on.
What I did for this problem was: make a DAG using the nesting relation and finding the longest path in it. It has three phases: one for sorting the dimensional values for each boxes, which takes O(n d log d), making the DAG, which takes O(n^2 d) and finding its longest path (dynamic programming is used here), with O(n^2).
So, the total complexity of the algorithm is O(n d log d + n^2 d), here's the accepted code:
EDIT: The C++ code tag can't handle it very well, http://pastebin.com/bgKgr7MH
Experienced Forum User, Published Author, Player
(42)
Joined: 12/27/2008
Posts: 873
Location: Germany
@Tub:
I didn't submit your solution, but if I understand correctly, I think it'll receive Wrong Answer.
Try this (the boxes are supposed to be at the sorting method you chose):
Experienced Forum User, Published Author, Player
(42)
Joined: 12/27/2008
Posts: 873
Location: Germany
Your method for checking if a box nests each other is entirely correct, but you still need to find a way to output the largest nesting sequence. (EDIT: the method is almost correct, it's smaller, not smaller or equal).
And in that problem, the value of n could go as high as 1000, my solution passed with a time of 0.012 sec.
Experienced Forum User, Published Author, Player
(42)
Joined: 12/27/2008
Posts: 873
Location: Germany
ALAKTORN wrote:
I wanted a bottom screen only encode to upload to my YT for it, but not knowing how to do it, I'm asking you guys if anyone can be kind enough to provide that for me, here I made a .rar containing ROM+save+input file: <link>
Please remove this asap, it's not allowed to share ROM files in the forums.
Experienced Forum User, Published Author, Player
(42)
Joined: 12/27/2008
Posts: 873
Location: Germany
Perhaps I should redo the run and take some extra time to finish the game like this or this and aim for the category "no save corruption that doesn't look like Yellow".
Or maybe I should decide to ignore the ZZAZZ glitch and end up with a route that could be thought of "the 100% run that doesn't catch all pokemon" (that's exactly what the published movie is at this point).
I don't intend to be rude, but in all honesty, this criticism seems to me as "I think this was broken too much, perhaps by imposing more arbitrary restrictions you could make me have a different form of entertainment, even if this would almost double the time of this submission".
Also, seeing from the low entertainment rating that glitchfree RPG runs have, I think 90% of the people won't like such a run because "it's too long and too boring". Since the 100% run was brought up, I prefer not having a movie that lasts a little more than 3 hours (testrun finished at 4h) eliminate a 40-minute category, 90% of viewers won't even watch the 100% run.
Just to finish, I truly believe that most people who think the only interesting part is the last glitch and this run is Yellow 40 mins longer will like the published Blue run even less if they watch it.


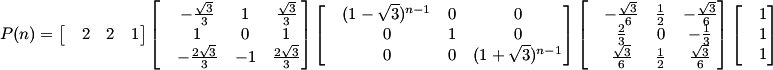 We can do less operations by using the associative property, after all computation is done, we finally get to the general term:
We can do less operations by using the associative property, after all computation is done, we finally get to the general term:
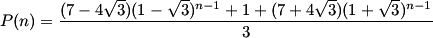 Thus, the amount of pretty sequences of length 2011 is given by substituting n=2011 in the above formula.
If you were to allow programming to find the decimal digits of P(n), this can be done in O (log n) operations with no precision loss by an application of a cross function. It will use multiplications, which are slower than additions, but if GMP uses Karatsuba multiplication or its variants, it will be done quite efficiently.
I haven't tested
Thus, the amount of pretty sequences of length 2011 is given by substituting n=2011 in the above formula.
If you were to allow programming to find the decimal digits of P(n), this can be done in O (log n) operations with no precision loss by an application of a cross function. It will use multiplications, which are slower than additions, but if GMP uses Karatsuba multiplication or its variants, it will be done quite efficiently.
I haven't tested 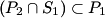 ,
, 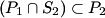 and
and 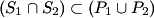 .
Prove that
.
Prove that 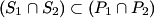 .
3) A sequence of natural numbers is "pretty" if, for every consecutive terms ai, ai+1 in the sequence, |ai - ai+1| <= 1 and no number other than 1, 2, 3, 4 or 5 appears in the sequence.
For example, (3, 4, 4, 5, 4, 3, 2, 2, 3, 2) is a pretty sequence.
How many pretty sequences of 2011 numbers exist?
.
3) A sequence of natural numbers is "pretty" if, for every consecutive terms ai, ai+1 in the sequence, |ai - ai+1| <= 1 and no number other than 1, 2, 3, 4 or 5 appears in the sequence.
For example, (3, 4, 4, 5, 4, 3, 2, 2, 3, 2) is a pretty sequence.
How many pretty sequences of 2011 numbers exist?