Experienced Forum User, Published Author, Player
(42)
Joined: 12/27/2008
Posts: 873
Location: Germany
Ah, so that's what you wanted the addresses for...
If you have trouble with Lua syntax, here's a small revision of your script using the loops and a small trick to get the bit-sum:
Language: Lua
function popcount(x)
local counter = 0
while x>0 do
x = x - AND(x,-x)
counter = counter + 1
end
return counter
end
function showCaught()
local startAddress = 0xD2F7
local caught = 0
for i=0,18 do
caught = caught + popcount(memory.readbyte(startAddress+i))
end
gui.text(140,130,caught)
end
gui.register(showCaught)
I know that there's at least one DS Castlevania run published with a Lua encode...
Experienced Forum User, Published Author, Player
(42)
Joined: 12/27/2008
Posts: 873
Location: Germany
Apparently, it's infinite, I used a Gameshark to always get heads and I filled the entire screen with circles, I didn't continue to see if it would eventually get out of VRAM and start corrupting other parts, but certainly, since it's not possible to get more than 20 flips, even if it does corrupt, it wouldn't have much use, unfortunately...
Experienced Forum User, Published Author, Player
(42)
Joined: 12/27/2008
Posts: 873
Location: Germany
Pokedex addresses are in the range D2F7-D31C. It's stored as two separate pokedexes: "Own" and "Seen", in that order, 19 bytes for each. Each byte has a value for eight pokemon, if the bit is 0, not registered, if 1, it's registered.
Experienced Forum User, Published Author, Player
(42)
Joined: 12/27/2008
Posts: 873
Location: Germany
Uh, I'm sorry, I suck at evaluating things by hand. I had to solve the recurrence...
Anyway, the solution for that recurrence is qk=k q1 - k(k-1)/2, solving for q11 gives:
{0, 5, 9, 12, 14, 15, 15, 14, 12, 9, 5, 0}
It's all so clear now! This is a parabola, so this is probably the motion of an object suffering gravitational force after being thrown with horizontal speed.
EDIT: Thinking better, it must be a free fall, since L = mv^2/2 +mg x
For part 2, well:
We have to find the extrema of int(L(q,q',t)dt). This occurs when d/dt (del L / del q' ) - del L / del q = 0
In this problem, if we let Dqi denote qi-qi-1, we have to find the extrema of sum(Fi(qi,Dqi),i), using some strange notation, that happens when D(del Fi/del qi) = D(del Fi/del Dqi), or something like that. Is the analogy clearer now?
Experienced Forum User, Published Author, Player
(42)
Joined: 12/27/2008
Posts: 873
Location: Germany
Bobo the King wrote:
The last problem reminded me of one that I dreamed up a while ago.
1) Find a difference equation for q such that the sum
sum( f(qi, qi-qi-1, i) )
is minimized for an arbitrary function f. In the sum, i ranges from 1 to N and you may assume that q0 and qN are both given so that the problem is well-posed. (Hint: Take your partial derivatives carefully!)
2) Introduce a symbol (if you haven't already done so) that will make your solution to (1) instantly familiar to any physicist or mathematician with a background in calculus of variations.
3) Apply your solution to the function
f=2qi - (qi-qi-1)^2
subject to the boundary conditions q0=0, qN=0, and N=11. What physical problem is this analogous to?
1) Since the function depends on i, I like to think of this as sum(Fi(qi,qi-qi-1)). The function you are trying to minimize then depends on the q's. I'll introduce: L(q0,q1,...,qn) = L(q)
This will be extremized when the gradient of L is the null vector. Taking the partial derivative del L / del qk, k between 0 and n-1, we see that only Fk and Fk+1 depend on qk. to find the partial derivative, we can apply the chain rule for multivariate functions. Assuming Fi(x,y).
del Fk(qk,qk-qk-1) / del qk + del Fk+1(qk+1,qk+1-qk) / del qk= del Fk(qk,qk-qk-1) / del x + del Fk(qk,qk-qk-1) / del y - del Fk+1(qk+1,qk+1-qk) / del y = 0
For k=n:
del Fn(qn,qn-qn-1) / del qn = del Fn(qn,qn-qn-1) / del x + del Fn(qn,qn-qn-1) / del y
If the Fi's are known, you have these difference equations. If you have two of the q's and the equation has solutions, you can find all of them.
2) Since you use q's, I think that hints to Lagrange's or Hamilton's interpretation of classical mechanics, so I used L to denote the function of all q's. In variational calculus, we deal with functionals and attempt to minimize the integral int(F(y,y',x)dx), deriving a differential equation. The difference here is that we are dealing with a finite sum instead of an integral and a difference equation instead of a differential one, hence we can use simple multivariate calculus.
3) F(x,y) = 2x - y2
del F/ del x = 2
del F/del y = -2y
del F(qk,qk-qk-1) / del x + del F(qk,qk-qk-1) / del y - del Fk+1(qk+1,qk+1-qk) / del y = 0
This implies 2 - 2(qk-qk-1) + 2(qk+1-qk) = 0 -> 1 - 2qk + qk-1 + qk+1 = 0 -> qk+1 = 2qk - qk-1 - 1
With q0=0, we eventually reach q11=3q1-11=0 -> q1 = 11/3, with solution:
{0, 11/3, 19/3, 8, 7, 6, 5, 4, 3, 2, 1, 0}
I have no idea what physical problem this is analogous to... One could tell by the function F, I think, perhaps a catenary? I don't know...
Experienced Forum User, Published Author, Player
(42)
Joined: 12/27/2008
Posts: 873
Location: Germany
Just posting here to say that FractalFusion and I are having a deeper look into this game. The luck manipulation in the current run was made mostly through experimentation, so now we're trying to do it more analytically. An improvement to it might be on its way. Meanwhile, here's some random vid I made after deciphering a little of the RNG:
Link to video
Experienced Forum User, Published Author, Player
(42)
Joined: 12/27/2008
Posts: 873
Location: Germany
1- By contradiction:
Suppose there exists a scalene triangle formed by points X, Y and Z. By the metric's property D(x,y) <= max{D(y,z),D(x,z)}. First, we assume that D(y,z) is larger and we have D(x,y)<=D(y,z) and since they are different D(x,y)<D(y,z). We now have D(y,z)>D(x,y) and D(y,z)>D(x,z), so D(y,z) is the largest distance. However, from the property D(y,z)<=max{D(x,y),D(x,z)}, this is absurd.
The case where D(x,z) is larger is completely analogous and also leads to an absurd. Therefore, scalene triangles don't exist and they must all be isosceles.
2- Let's consider the open ball centered at C with radius r Br(C). Consider an arbitrary point P inside the ball, that is, D(C,P)<r. We now pick an arbitrary point in the metric space X and consider two cases:
a) D(C,X)<r: We have D(P,X)<=max{D(C,X),D(C,P)}<r
b) D(C,X)>=r: We have max{D(P,X),D(C,P}>=D(C,X). Since D(C,P)<r and D(C,X)>=r, for the maximum of the set to be larger than or equal to D(C,X), we must have D(P,X)>D(C,P) and so, D(P,X)>=D(C,X)>=r
From this, we conclude that, taking any point P inside the ball, for any point X in space, D(C,X)<r if and only if D(P,X)<. Thus, Br(C) = Br(P), so P can also be considered the center of the ball. For a closed ball, just separate into D(C,X)<=r and D(C,X)>r.
Experienced Forum User, Published Author, Player
(42)
Joined: 12/27/2008
Posts: 873
Location: Germany
Ah, thanks, I was being more strict with the nomenclature. A BFS is done like this:
mark all vertices as not visited
enqueue root
mark root as visited
while queue not empty do
dequeue the vertex v
for each (v,w) in the graph do
if w is not visited then
enqueue w
mark w as visited
end
end
end
If you keep a linked list (or something like that) to keep track of who called each vertex, you can get your path by following the nodes starting from the destination. You can even stop the search when you reach the destination.
I never doubted the correctness of your algorithm, just notice that there are some significant differences between your code and the BFS, not just in terms of implementation (copying an entire table at each iteration vs using a queue). You start the search in two nodes and constantly query the structure to know if there's any intersection. Although the idea of traversing the nodes in the right order is there, saying that the script executes a breadth-first search is a little inaccurate, "essentially" is different from "is". It's possible to come up with other algorithms that use a similar idea with sub-optimal complexity and calling them all a BFS would make the nomenclature very imprecise.
If the actual graph is too small for this change to make a difference, then I wish I hadn't brought this up. Seeing as FCEUX is the main problem, you could disassemble the ROM to know the game's mechanics and run a simulation on a compiled language, assuming this is accepted, of course. And I abstained from voting.
Experienced Forum User, Published Author, Player
(42)
Joined: 12/27/2008
Posts: 873
Location: Germany
Regarding to BFS, I was talking about this, in function shortestpaths, to find the shortest path for only one graph, not the entire game:
Language: Lua
map[0][initial]={{}}
map[1][final]={{}}
local depth=0
while not(incommon(map[0],map[1])) do
for i=0,47 do
if map[depth%2][i] and #map[depth%2][i][1]==math.floor(depth/2) then
for j=0,3 do
local destination=graph[i][j]
map[depth%2][destination]={}
local temp=table.copy2(map[depth%2][i])
for k=1,#temp do
table.insert(temp[k],#temp[k]*(1-depth%2)+1, destination*(1-depth%2)+i*(depth%2))
map[depth%2][destination][#map[depth%2][destination]+1]=table.copy(temp[k])
temp=table.copy2(map[depth%2][i])
end
end
end
end
depth=depth+1
end
Honestly, I'm not very sure about what this does, but it doesn't look like a BFS.
Also, any optimization problem can be turned into a collection of decision ones multiplying the complexity by O(log d), where d is the max amount of turns it takes to finish. You can turn your problem into "can I finish the game using d steps?" and binary search on d. This is just meant to give you some thoughts about botting it if you intend to do this again, I give no guarantee that backtracking can be used to help. It's just something to think about.
Experienced Forum User, Published Author, Player
(42)
Joined: 12/27/2008
Posts: 873
Location: Germany
Bobo the King wrote:
Yes, it is a very rudimentary form of dynamic programming (I don't consider myself a programmer and I never pass up an opportunity to emphasize that). As such, it's virtually certain that this run is not perfect. If I could execute my program to a search depth of 80 (not possible!), it would theoretically be perfect. This run was made by setting the depth to 1 and the breadth to 2, but if this is somehow accepted, I would like to improve it by increasing the depth to 3 and the breadth to 4 or so. To produce this run, I left my computer on overnight and even then it was only able to complete relatively small chunks (roughly 30 levels) at a time and it became very hot. I can improve it (maybe by 10 minutes or so), but it will require doing just three levels at a time and working on it for about a month before stitching all the movies together.
Experienced Forum User, Published Author, Player
(42)
Joined: 12/27/2008
Posts: 873
Location: Germany
Derakon: There's another way to do this check for general convex polygons, it's a classical problem in computational geometry. It uses O(n) preprocessing time to answer queries at O(lg n) speed.
Preprocessing:
1. Pick an arbitrary point in the polygon P0 (usually the one with smallest y, breaking the tie with the smaller x).
2. For each point Pk, evaluate the angle that the line (Pk - P0) makes with an arbitrary line (normally the x axis).
Assuming the polygon is convex, the angles will be in increasing order.
Querying
1. Given a point P, find the lowerbound/binary search for the angle of the line (P-P0) with the arbitrary line.
2. Let Pn be the point with angle smaller than P and P(n+1) the one with grater angle.
3. Evaluate (Pn-P0) x (P(n+1) - P0) dot (Pn - P) x (P(n+1)-P). If positive, the point is inside the polygon.
Of course, there are a lot of checks for degenerate cases, which makes computational geometry very annoying, but the main idea is there.
This problem is the most interesting one I've come across that uses those concepts, unless you want to actually submit a solution to it, in this case the precision errors will tear your brain apart: http://uva.onlinejudge.org/external/118/11836.pdf
Experienced Forum User, Published Author, Player
(42)
Joined: 12/27/2008
Posts: 873
Location: Germany
Knowing a little of the RNG mechanics, I can fully appreciate how massive the improvement of this submission really is, both in the technical and entertainment aspects. It's astounding to manipulate the optimal Taillow so smoothly given that RSE's entropy is much more limited than its predecessors and there are more things to be concerned about.
FractalFusion gives a lecture on luck manipulation here and, as a consequence, wins battles impressively. I found the old run a little boring, but IMO, this new movie is among the best non-glitched RPG runs of the site. Yes vote.
Experienced Forum User, Published Author, Player
(42)
Joined: 12/27/2008
Posts: 873
Location: Germany
I'd got to Blaine some weeks ago, but due to some mistakes with box manipulation, I have to redo him and the entire pokemon mansion, then exam period started and I haven't touched this for a long while. Mukki's completely right, we have to finish this, when Life gives us a break. Besides, I don't think that new glitch can really improve Pewter, fighting Gary takes a lot of time.
Here goes it (I forgot I needed to trade Slowbro for Lickitung and switched the box with Slowbro into inactivity, losing some time, that was the only mistake, but means redo): http://dehacked.2y.net/microstorage.php/info/1091411297/POKEBLUE.vbm
And sorry for completely forgetting about this thread from time to time...
Experienced Forum User, Published Author, Player
(42)
Joined: 12/27/2008
Posts: 873
Location: Germany
Since we are two pages after and it's highly unlikely that anyone will attempt my problem, I'll do a part of it.
p4wn3r wrote:
Suggestion: Use a change of variables that rotates the axes by an angle of 45º
Hey, that's useful!
Let's use two new axes u and v that are rotated 45º counterclockwise to x and y. We can do this algebraically by using a rotation matrix:
However, to use a change of variables, we need to know x and y in terms of u and v. Fortunately, any rotation matrix is orthonormal and its inverse is simply its transpose:
In order to do the variable change, we need to evaluate the absolute value of the determinant of the Jacobian matrix and multiply it by integrand:
The function to be integrated, in this new coordinate system becomes:
Now, for the hardest part when working with multiple integrals, finding its bounds. For this, we use a geometric argument. In the xy-system, the domain of integration is the square [0,1] x [0,1]. In the uv-system, it's still a square, but it's rotated so that the u-axis cuts its diagonal, having positive orientation from u=0 to u=sqrt(2) (the length of the diagonal). Using analytic geometry, we can see that the square's sides are determined by the lines of equations:
v = u
v = -u
v = sqrt(2) - u
v = -sqrt(2) + u
Now, the order of integration, we need to specify it so that we can apply Fubini's theorem and iterate the integral. Integrating on u first allows us to express the entire region in one integral, but the integrand won't have an elementary primitive, so we're screwed. Then, let's try integrating on v first.
For this, we separate the rotated square into two regions, one from 0<u<sqrt(2)/2 and the other from sqrt(2)/2<u<sqrt(2). In the first one, keeping u fixed, we see that the smallest v is on the line v = -u and the largest on v=u. For the second one, still keeping u fixed, the smallest v = -sqrt(2) + u and the largest v = sqrt(2) - u. Thus, we sum the integrals on those two regions to obtain:
Anyone up for it now?
Experienced Forum User, Published Author, Player
(42)
Joined: 12/27/2008
Posts: 873
Location: Germany
I'll prove that the universal set doesn't exist (as long as ZFC is considered) by reductio ad absurdum.
Suppose the universal set U exists. Therefore, by the axiom of specification, the following set exists:
S = {x E U | x is not an element of x }
Since S E U, we can conclude that S is an element of S iff S is not an element of S, which is absurd.
Therefore, the universal set doesn't exist. Since the question assumes that a universal set exists (a false proposition), everything can be proved and both yes/no answers will be correct.
Experienced Forum User, Published Author, Player
(42)
Joined: 12/27/2008
Posts: 873
Location: Germany
Tub wrote:
I could solve the die-case by independently examining 6 different random variables: Xi = 1 when the die says i, 0 otherwise.
Would my confidence interval for throwing a 1 be any different if 12 dice throws are either each side twice, or one twice and six ten times? My guess for P(X=1) is 1/6 in both cases, but would a high amount of sixes make me any more or less confident about that guess? I don't think so, but as always I may be wrong.
It's just that we're generally more concerned about the entire probability distribution than one value itself. In higher dimensions, the notion of confidence intervals can be generalized to the entire probability function because it gives a better idea of how good your data is than simply evaluate the uncertainty for each variable, which makes it look worse than it actually is. The main difference is that the gaussian function has radial symmetry and can be reduced to a univariate integral, while the polynomial one can't.
Tub wrote:
Quote:
Now I do this again, 100 times, getting 10 heads.
x_m still 0.1
sigma_m = sqrt( ( 90*0.1^2 + 10*0.9^2) / 100*101) = 0.02985
I'm getting 77.6% instead of 68.27, though with summands like
(90 choose 45)/56 * x^56
rounding errors are bound to be problematic. I'll try again tomorrow with a proper math library.
Any hope of having this as a neat formula in OOCalc went out the window, anyway. :/
I figured this could happen, floating point hates polynomials of high degrees. I'm getting 67,93% for 1 SD and 94,02% for 2 SD's in Mathematica 7. Maybe you could calibrate your program with those values. Good luck.
Experienced Forum User, Published Author, Player
(42)
Joined: 12/27/2008
Posts: 873
Location: Germany
Well, I tried my best to explain the theory behind confidence intervals, surely the order matters if you make a partition, but if you count the number of subsets full of 0's and compare that have mixed 1's and 0's, you'll see the former is extremely small in comparison to the latter, even for small n, so the chance of your estimation being screwed up by this fact can be ignored.
It's also of my opinion that stochastics is an overly simplified and "ugly" field of mathematics and I won't stand to defend it. However, when you acquire some knowledge about these subjects, you see that there are problems that mankind will probably never be able to solve exactly and approximation methods are more than necessary.
The use of Gaussian distribution for this problem is very popular, I've never come across your approach, I think it's correct and easy to compute for the coin's case, but for the case of a dice, you'd have to do a five-dimensional integral, and that's very hard stuff. If you think such integration suits your needs best, that's a polynomial function, expand the (1-p) term by Newton's binomials and multiply it by p^m. The integral of a polynomial function is one of the most elementary ones.
Experienced Forum User, Published Author, Player
(42)
Joined: 12/27/2008
Posts: 873
Location: Germany
Tub wrote:
Does it even make sense to model a probability as gauss/normal distributed, ignoring the known boundaries of [0, 1]?
Rigorously speaking, no. You have to model your experiment so that gaussian distribution is a good approximation to it.
If you consider a sample consisting of n coin tosses, you'll never have a continuous possible space of probabilities, because the possible results will always be a multiple of 1/n and, thus, countable. In your example, you're taking a sample as only one coin toss, that has only two possible values (0 or 1) and that's far from a continuous model.
I'd tackle it like this: get one sample as a hundred coin tosses, x_i = number of heads / 100. Do this to n samples and evaluate the standard deviation and everything else. For sufficiently large n, the real probability distribution around 3 SD's from the mean will behave like a Gaussian and you can apply those results. I remember having done a similar experiment to this by throwing 50 dice in each sample and counting the ratio of the number of 1's, the result was pretty accurate iirc.
EDIT:
Language: C++
#include <stdio>
#include <math>
#include <stdlib>
#include <time>
int v[100];
double x[5];
int main(){
double fav,mean,sigmaM;
srand(time(NULL));
for (int i=0; i<5; i++){
for (int j=0; j<100; j++) v[j]=rand()%2;
fav=0;
for (int j=0; j<100; j++){
if (v[j]==0) fav+=(1.0/100);
}
x[i]=fav;
}
mean=0;
for (int i=0; i<5; i++) mean+=x[i];
mean/=5;
sigmaM=0;
for (int i=0; i<5; i++) sigmaM+=pow(x[i]-mean,2);
sigmaM/=(5*4);
sigmaM=sqrt(sigmaM);
printf("%lf +- %lf\n",mean,2.13*sigmaM);
getchar();
return 0;
}
Here's a virtual experiment using an RNG to simulate 100 coin tosses and to evaluate the 90% certainty with five samples. Since five is a small quantity, I used the value in a table for finite amounts of testing, which I have in hands now. I can pass it to you if you want, but with a computer you can do a large amount of tests so that the value for infinite measures is good enough. In practice, to obtain better approximation, it's usually better to increase the size of the sample than to increase the amount of observations.
Experienced Forum User, Published Author, Player
(42)
Joined: 12/27/2008
Posts: 873
Location: Germany
Having a zero standard deviation doesn't mean your guess is 100% correct, it lets the formula undefined. The error function tends to zero everywhere when the standard deviation is zero (except at x=0, but the discontinuity has no effect on integration). If you were to divide the finite integral over the infinite one, you'd get 0/0, which is undefined. For bigger amounts, the chance of the standard deviation being zero is very rare, so the formula is generally more conclusive.
Experienced Forum User, Published Author, Player
(42)
Joined: 12/27/2008
Posts: 873
Location: Germany
The math behind confidence intervals is not as ugly as it seems.
Supposing that your sample is equivalent to throwing a lot of dice into the air, taking notes of their values and dividing the desired event over the total amount thrown, you basically have a perfect measuring instrument for the sample, thus systematic errors are zero (actually in real life there are rounding errors, you may decide to include them, but most of the time they can be considered negligible in comparison to statistical errors).
So, you only need to consider statistical errors. I'll consider that the values are in Gaussian distribution (I think English literature most commonly refers to it as normal distribution). Suppose you have the results of n samples taken the way I described before. Then take the mean of all samples xm. Define the standard deviation of this data collection as
sigma = sqrt(sum((xi - xm)2)/(n-1))
The standard deviation measures how spread the data collected from all samples is, the larger it is, the higher is your uncertainty that their mean can correctly describe the value measured.
Anyway, you basically want to take the mean of all those samples and take it as the probability of the event. To measure how good this approximation is, you take the standard deviation of the mean, defined by:
sigmam = sigma/sqrt(n) = sqrt(sum((xi - xm)2)/n(n-1))
It's intuitive to use this value because if two data have the same standard deviation, but data A has more samples than data B, the mean value of A is more reliable than the one we got from B.
Now, probability under Gaussian distribution is modeled through a function like: a exp(-bx2) and the probability that a value measured next will be within an interval (-a,a) is the area of the integral of this function divided by the integral of it in (-inf,inf), which is something proportional to sqrt(pi).
The integral, however, cannot be expressed analytically in finite intervals, so numerical methods are used to evaluate the function and its inverse. What's necessary to know is that if you take the interval as (-sigmam,sigmam), and consider the amount of measures so big that it can be considered infinite, you'll get around 68% of certainty in your value in that interval. You can raise this certainty by making the interval larger by multiplying sigmam by a constant. Normally, 90% and 95% certainty are used.
Since the values need to be evaluated numerically, they often come in a table:
50% 0,674
68,27% 1,000
80% 1,282
90% 1,645
95% 1,960
95,45% 2,000
99% 2,576
99,73% 3,000
These values, like I said before, consider an infinite amount of measures. However, if this value is not very big, you need to use a table for finite amounts, which I don't have access atm.
In short, to evaluate the confidence interval, find sigma_m as defined by the formula, multiply it by one of the constants given that give the certainty you need and take this result as the uncertainty.
Experienced Forum User, Published Author, Player
(42)
Joined: 12/27/2008
Posts: 873
Location: Germany
The only existing example of that is Geiger's SNES9x build, for example the Chrono Trigger TAS would be 15 minutes faster if that emulator were used instead. There's no emulator capable to do a reset at any instruction for GBx afaik, I'm also not sure if a TAS done on it would be accepted if it existed, since the abuse of such feature would allow save-corruption exploits for virtually any game as long as you can do hash collisions (if they actually check some form of hash on the save file).
Experienced Forum User, Published Author, Player
(42)
Joined: 12/27/2008
Posts: 873
Location: Germany
Torchickens wrote:
p4wn3r wrote:
RingRush wrote:
1. Get a level 0 bad clone (involves the classic cloning glitch, resetting at the exact right time...there is more on this on plenty of sites).
Do you have a vbm getting this bad clone?
I tried many times, but couldn't get a lvl0 bad clone on VBA-rr no matter which frame I reset.
In Pokémon Crystal, it is around (well popularly believed to be) after the word 'POWER.' is written (after the full stop), did you try resetting around there?
http://www.youtube.com/watch?v=BIz1RAg25yM
Yes, I binary searched for the frame to reset both in Gold and Crystal. The only thing close to a bad clone I've got was a pokemon with tons of question marks in its name, sometimes it had also nines, it depended on the box.
In Crystal, I got it 140 frames after the save is confirmed, it's around 1/3 of a second after POWER is displayed. I don't remember the Gold version, but it was shortly after confirming the save, no letters were displayed.
I've tried this in many boxes, with varying quantities of pokemon, some of them had been filled, others hadn't. Basically tried every possibility I've come across in the internet. So far, in no VBA-rr version, I've got a lvl0 bad clone.
EDIT: I didn't try it in the latest v24 branch klmz released, I'll try it this weekend.
Experienced Forum User, Published Author, Player
(42)
Joined: 12/27/2008
Posts: 873
Location: Germany
Parece que não reuniu muito interesse, hehe.
Talvez você poderia ser mais específico, em que tipo de jogo você acha que deveria ser feito esse trabalho?
Sei que alguns títulos que foram bem populares no Brasil, como Metal Warriors, Silent Hill, Medal of Honor ainda estão sem TAS.
Com certeza há muito mais exemplos, mas eu não era assim tão viciado para saber todos.


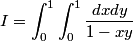
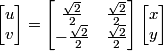 However, to use a change of variables, we need to know x and y in terms of u and v. Fortunately, any rotation matrix is orthonormal and its inverse is simply its transpose:
However, to use a change of variables, we need to know x and y in terms of u and v. Fortunately, any rotation matrix is orthonormal and its inverse is simply its transpose:
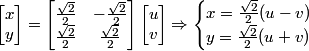 In order to do the variable change, we need to evaluate the absolute value of the determinant of the Jacobian matrix and multiply it by integrand:
In order to do the variable change, we need to evaluate the absolute value of the determinant of the Jacobian matrix and multiply it by integrand:
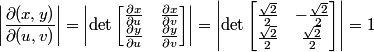 The function to be integrated, in this new coordinate system becomes:
The function to be integrated, in this new coordinate system becomes:
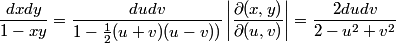 Now, for the hardest part when working with multiple integrals, finding its bounds. For this, we use a geometric argument. In the xy-system, the domain of integration is the square [0,1] x [0,1]. In the uv-system, it's still a square, but it's rotated so that the u-axis cuts its diagonal, having positive orientation from u=0 to u=sqrt(2) (the length of the diagonal). Using analytic geometry, we can see that the square's sides are determined by the lines of equations:
v = u
v = -u
v = sqrt(2) - u
v = -sqrt(2) + u
Now, the order of integration, we need to specify it so that we can apply Fubini's theorem and iterate the integral. Integrating on u first allows us to express the entire region in one integral, but the integrand won't have an elementary primitive, so we're screwed. Then, let's try integrating on v first.
For this, we separate the rotated square into two regions, one from 0<u<sqrt(2)/2 and the other from sqrt(2)/2<u<sqrt(2). In the first one, keeping u fixed, we see that the smallest v is on the line v = -u and the largest on v=u. For the second one, still keeping u fixed, the smallest v = -sqrt(2) + u and the largest v = sqrt(2) - u. Thus, we sum the integrals on those two regions to obtain:
Now, for the hardest part when working with multiple integrals, finding its bounds. For this, we use a geometric argument. In the xy-system, the domain of integration is the square [0,1] x [0,1]. In the uv-system, it's still a square, but it's rotated so that the u-axis cuts its diagonal, having positive orientation from u=0 to u=sqrt(2) (the length of the diagonal). Using analytic geometry, we can see that the square's sides are determined by the lines of equations:
v = u
v = -u
v = sqrt(2) - u
v = -sqrt(2) + u
Now, the order of integration, we need to specify it so that we can apply Fubini's theorem and iterate the integral. Integrating on u first allows us to express the entire region in one integral, but the integrand won't have an elementary primitive, so we're screwed. Then, let's try integrating on v first.
For this, we separate the rotated square into two regions, one from 0<u<sqrt(2)/2 and the other from sqrt(2)/2<u<sqrt(2). In the first one, keeping u fixed, we see that the smallest v is on the line v = -u and the largest on v=u. For the second one, still keeping u fixed, the smallest v = -sqrt(2) + u and the largest v = sqrt(2) - u. Thus, we sum the integrals on those two regions to obtain:
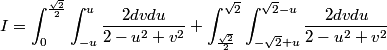 Anyone up for it now?
Anyone up for it now?